"4.Внутреннее устройство Windows (гл. 12-14)" - читать интересную книгу автора (Руссинович Марк, Соломон Дэвид)
ГЛABA 14 Анализ аварийного дампа
Почти каждый пользователь Windows слышал о так называемом «синем экране смерти» (blue screen of death, BSOD) или даже видел его. Этим зловещим термином называют экран с синим фоном, показываемый при крахе или остановке Windows из-за катастрофического сбоя или внутренней ситуации, из-за которой стала невозможной дальнейшая работа системы.
B этой главе мы рассмотрим основные причины краха Windows, опишем информацию, выводимую на «синем экране» и расскажем о различных параметрах конфигурации, управляющих созданием
Крах Windows (остановка системы и вывод «синего экрана») может быть вызван следующими причинами:
• необработанным исключением, вызванным драйвером устройства или системной функцией режима ядра, например из-за нарушения доступа к памяти (при попытке записи на страницу с атрибутом «только для чтения» или чтения по еще не спроецированному и, следовательно, недопустимому адресу);
• вызовом процедуры ядра, результатом которой является перераспределение процессорного времени из-за, например, ожидания на занятом объекте диспетчера ядра при IRQL уровня «DPC/dispatch» или выше (об IRQL см. главу 3);
• обращением к данным на выгруженной из памяти странице при IRQL уровня «DPC/dispatch» или выше (что требует от диспетчера памяти ждать операции ввода-вывода, а это, как уже говорилось, невозможно на таких уровнях IRQL, поскольку требует перераспределения процессорного времени);
• явным вызовом краха системы драйвером устройства или системной функцией (через функцию
• аппаратной ошибкой, например ошибкой аппаратного контроля или появлением немаскируемого прерывания (Non-Maskable Interrupt, NMI). B Microsoft проанализировали аварийные дампы, отправляемые пользователями Windows XP на сайт Microsoft Online Crash Analysis (OCA) (о нем еще пойдет речь в этой главе), и обнаружили, что причины краха систем распределяются, как показано на диаграмме на рис. 14-1 (по состоянию на апрель 2004 года).
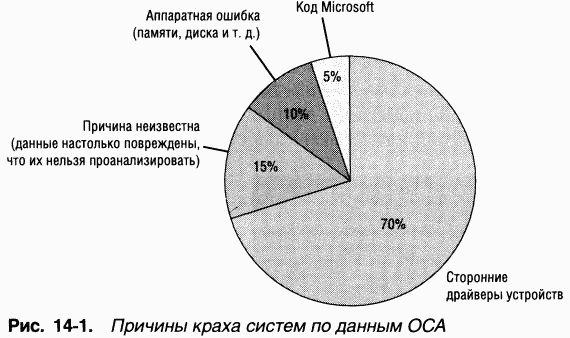 |
Когда драйвер устройства или компонент режима ядра вызывает необрабатываемое исключение, перед Windows встает трудная дилемма. Какая-то часть операционной системы, имеющая право доступа к любым аппаратным устройствам и любому участку памяти, сделала нечто такое, чего делать нельзя.
Ho почему при этом обязательно должен произойти крах Windows? Почему бы не проигнорировать это исключение и не позволить драйверам работать дальше, как ни в чем не бывало? Ведь не исключено, что ошибка носила локальный характер и соответствующий компонент как-нибудь сумеет после нее восстановиться. Ho гораздо вероятнее, что обнаруженное исключение связано с более серьезными проблемами, например с повреждением памяти или со сбоями в работе оборудования. Тогда дальнейшее функционирование системы скорее всего приведет к еще большему числу исключений и порче данных на дисках и других периферийных устройствах, а это слишком рискованно.
Независимо от причины реальный крах системы вызывается функцией
 |
B Windows 2000 KeBugCheckEx выводит текстовое представление стопкода, его числовое значение и четыре параметра вверху «синего экрана», но в Windows XP и Windows Server 2003 числовое значение и параметры показываются внизу «синего экрана».
B первой строке выводится стоп-код и значения четырех дополнительных параметров, переданных в
Хотя стоп-кодов более сотни, большинство из них очень редко или вообще никогда не встречается в рабочих системах. Причины краха Windows могут быть представлены довольно небольшой группой стоп-кодов. Кроме того, не забывайте, что смысл дополнительных параметров зависит от конкретного стоп-кода (но не для всех стоп-кодов предусматривается расширенная информация, передаваемая через эти параметры). Тем не менее, анализ стоп-кода и значений параметров (если таковые есть) может, по крайней мере, помочь в выявлении сбойного компонента (или аппаратного устройства, вызывающего крах).
Информацию, необходимую для интерпретации стоп-кодов, можно найти в разделе «Bug Checks (Blue Screens)» справочного файла Windows Debugging Tools. (Сведения о Windows Debugging Tools см. в главе 1.) Кроме того, можно поискать стоп-код и имя проблемного устройства или приложения в Microsoft Knowledge Base
«Синие экраны» часто возникают после установки нового программного обеспечения или оборудования. Если вы видите «синий экран» сразу после установки нового драйвера на раннем этапе перезагрузки, то можете вернуть прежнюю конфигурацию системы, нажав клавишу F8 и выбрав из дополнительного загрузочного меню команду Last Known Good Configuration (Последняя удачная конфигурация). Тогда Windows использует копию раздела реестра, где были зарегистрированы драйверы устройств (HKLM\SYSTEM\ CurrentControlSet\Services) при последней успешной загрузке (до установки нового драйвера). Последней удачной конфигурацией считается последняя конфигурация, в которой успешно завершилась загрузка всех сервисов и драйверов и был выполнен минимум один успешный вход в систему. (O последней удачной конфигурации более подробно рассказывается в главе 5.)
Если это не помогает и вы по-прежнему видите «синие экраны», то самый очевидный подход — удалить компоненты, установленные перед появлением первого «синего экрана». Если после установки уже прошло некоторое время или вы одновременно добавили несколько устройств либо драйверов, обратите внимание на имена драйверов, указываемые в каких-либо параметрах на «синем экране». Если там есть ссылка на недавно установленные компоненты (например, Scsiport.sys в случае установки нового SCSI-диска), причина сбоя скорее всего связана именно с ними.
Имена многих драйверов весьма загадочны, но вы можете выяснить, какие устройства или программные компоненты соответствуют данному имени. Для этого просмотрите раздел реестра HKLM\SYSTEM\CurrentControlSet\ Services, где Windows хранит регистрационную информацию для каждого драйвера в системе, и попробуйте найти имя сервиса и сопоставленный с ним драйвер устройства. Описание найденного драйвера содержится в параметрах DisplayName и Description, здесь также описывается предназначение некоторых драйверов. Так, строка «Virus Scanner», обнаруженная в DisplayName, говорит о том, что драйвер является частью антивирусной программы. Список драйверов также можно вывести с помощью утилиты System Information (Сведения о системе): раскройте в ней узел Software Environment (Программная среда) и выберите System Drivers (Системные драйверы).
Однако чаще всего информации, сообщаемой стоп-кодом и сопоставленными с ним параметрами, недостаточно для устранения сбоя, приводящего к краху системы. Так, чтобы выяснить точное имя драйвера или системного компонента, вызывающего крах, может понадобиться анализ стека вызовов режима ядра. Поскольку в Windows после краха системы по умолчанию следует перезагрузка и у вас вряд ли будет время для изучения информации, представленной на «синем экране», Windows пытается записывать информацию о крахе системы на диск для последующего анализа. Эта информация помещается в файлы аварийного дампа.
По умолчанию все Windows-системы настраиваются на запись информации о состоянии системы на момент краха. Соответствующие настройки можно увидеть так откройте System (Система) в Control Panel (Панель управления), в окне свойств системы перейдите на вкладку Advanced (Дополнительно) и щелкните кнопку Startup And Recovery (Загрузка и восстановление). Ha рис. 14-3 показаны настройки по умолчанию для системы Windows XP Professional.
 |
При крахе системы может быть зарегистрировано три уровня информации.
• Complete memory dump (Полный дамп памяти) Полный дамп памяти представляет собой все содержимое физической памяти на момент краха. Для такого дампа нужно, чтобы размер страничного файла был равен, как минимум, объему физической памяти плюс 1 Мб (для заголовка). Этот параметр используется реже всего, так как в системах с большим объемом памяти страничный файл будет слишком велик. Windows NT 4 поддерживает только этот тип файлов аварийного дампа. Кроме того, этот параметр используется по умолчанию в системах Windows Server.
• Kernel memory dump (Дамп памяти ядра) Этот вариант дампа включает лишь страницы (как для чтения, так и для записи) режима ядра, находящиеся в физической памяти на момент краха. Страницы, принадлежащие пользовательским процессам, не включаются. Поскольку только код режима ядра может напрямую вызывать крах Windows, содержимое страниц пользовательских процессов обычно ничего не дает для понимания причин краха. Кроме того, все структуры данных, используемые при анализе аварийного дампа, — список выполняемых процессов, стек текущего потока и список загруженных драйверов — хранятся в неподкачиваемой памяти, содержимое которой запоминается в дампе памяти ядра. Заранее предсказать объем дампа памяти ядра нельзя, поскольку он зависит от объема памяти ядра, выделенной операционной системой и драйверами.
• Small memory dump (Малый дамп памяти) Размер этого дампа (вариант по умолчанию в системах Windows Professional) составляет 64 Кб (128 Кб в 64-битньгх системах). Такой дамп еще
Преимущество минидампа — его небольшой размер, благодаря которому, например, удобно передавать дамп по электронной почте. При каждом крахе в каталог \Windows\Minidump записывается файл с уникальным именем, начинающимся со строки «Mini», за которой идут дата и порядковый номер (например, Mini082604-01.dmp). Недостаток минидампов в том, что доя их анализа нужны именно те образы, которые использовались системой, сгенерировавшей дамп. (Даже для самого простого анализа, как минимум, необходима копия соответствующего Ntoskrnl.exe.) Это может стать проблемой, если вы анализируете дамп не на той системе, где он был создан. Однако на сервере символов Microsoft есть образы (и символы) для систем Windows XP и более поздних версий, поэтому можно задать в отладчике путь к образу, указывающий на сервер символов, и отладчик автоматически скачает нужные образы. (Конечно, на сервере символов Microsoft нет образов устанавливаемых вами драйверов сторонних производителей.)
Более существенный недостаток — такой дамп содержит ограниченное количество данных, что может помешать эффективному анализу. C минидампами можно работать, даже если вы настроили систему на генерацию дампа памяти ядра или полного дампа, — просто откройте более объемный дамп в Windbg и извлеките минидамп командой
Золотой серединой является дамп памяти ядра. Он содержит всю физическую память режима ядра, и, следовательно, позволяет вести анализ на том же уровне, что и полный дамп памяти, но не содержит код и данные пользовательского режима, обычно не относящиеся к проблеме, и поэтому имеет значительно меньший размер. Так, в системе с 256 Мб памяти под управлением Windows XP дамп памяти ядра занимает 34 Мб, а в системе с Windows XP и 1,5 Гб памяти этот дамп требует 72 Мб.
Когда вы настраиваете параметры дампа памяти ядра, система проверяет, достаточен ли размер страничного файла (в соответствии с таблицей 14-1), но это всего лишь оценочные размеры, поскольку предсказать размер дампа памяти ядра невозможно. Причина, по которой невозможно заранее определить размер дампа памяти ядра, состоит в том, что этот размер зависит от количества памяти режима ядра, используемой операционной системой и драйверами, выполнявшимися на компьютере в момент краха.
 |
Таким образом, может оказаться, что в момент краха системы страничный файл будет слишком мал для того, чтобы вместить дамп ядра. Если вы хотите узнать размер дампа ядра для своей системы, вызовите крах системы вручную: сконфигурируйте систему так, чтобы можно было вручную вызывать ее крах с консоли, или воспользуйтесь программой Notmyfault. (B этой главе описаны оба подхода.) После перезагрузки вы сможете проверить, сгенерирован ли дамп памяти ядра, и по его размеру оценить, каким должен быть размер страничного файла для вашего загрузочного тома. Для единообразия можно задавать для 32-разрядных систем размер страничного файла 2 Гб плюс 1 Мб, поскольку 2 Гб — максимальный размер адресного пространства режима ядра.
Наконец, даже если система в случае краха успешно записывает аварийный дамп в страничный файл, нужно, чтобы на диске хватало места для извлечения файла дампа. Если места не хватит, аварийный дамп пропадет, поскольку используемое им пространство страничного файла высвободится и будет перезаписано, когда система начнет использовать страничный файл. Если на загрузочном томе недостаточно места для сохранения файла memory.dmp, можно задать путь на другом жестком диске в диалоговом окне, показанном на рис. 14-3.
При загрузке система получает параметры аварийного дампа из раздела реестра HKLM\System\CurrentControlSet\Control\CrashControl. Если задана генерация дампа, система создает копию минипорт-драйвера диска (disk miniport driver), используемую для записи загрузочного тома в память и присваивает ей то же имя, что и у минипорта, но с префиксом «dump». Кроме того, система подсчитывает и сохраняет контрольную сумму для компонентов, используемых при записи аварийного дампа: скопированного минипорт драйвера диска, функций диспетчера ввода-вывода, записывающих дамп, и карты области, в которой располагается страничный файл на загрузочном томе. Когда вызывается функция
Когда SMSS в процессе загрузки активизирует постраничную подкачку, система проверяет, не содержится ли в страничном файле на загрузочном томе аварийный дамп, и защищает ту часть страничного файла, которая отведена под дамп. B результате на раннем этапе загрузки часть страничного файла или весь этот файл выводится из использования, что может вызвать системные уведомления о нехватке виртуальной памяти, однако это лишь временное явление. При дальнейшей загрузке Winlogon определяет, содержится ли дамп в страничном файле, вызывая недокументированную API-функцию
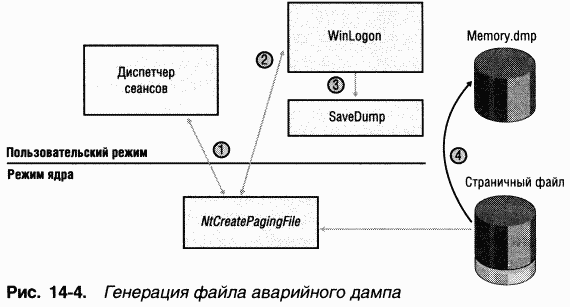 |
Как уже говорилось в главе 3, в Windows XP и Windows Server 2003 имеется механизм Windows Error Reporting, позволяющий автоматически передавать данные о сбоях процессов и системы на анализ в Microsoft (или на внутренний сервер отчетов об ошибках). По умолчанию этот механизм включен. Ha его работу можно повлиять, изменив поведение процесса Savedump, который выполняет следующую дополнительную операцию: при перезагрузке после краха проверяет, настроена ли система на отправку аварийного дампа на анализ в Microsoft (или на закрытый сервер). Ha рис. 14-5 показано диалоговое окно Error Reporting (Отчет об ошибках), которое можно открыть с вкладки Advanced (Дополнительно) апплета System (Система) панели управления. B этом диалоговом окне можно настроить параметры системных отчетов об ошибках, хранящиеся в разделе реестра HKLM\Software\ Microsoft\PCHealth\ErrorReporting.
 |
Рис. 14-5. Диалоговое окно настройки Error Reporting
После перезагрузки, вызванной крахом, Savedump проверяет несколько параметров, содержащихся в разделе ErrorReporting: Showui, DoReport и IncludeKernelFaults. Если все они имеют значение true, Savedump выполняет следующие операции по подготовке отчета о крахе системы к отправке на сайт Microsoft Online Crash Analysis (OCA) (или на внутренний сервер отчетов об ошибках, если это задано в настройках).
1. Если сгенерированный дамп не является минидампом, извлекает из файла дампа минидамп и записывает его в каталог по умолчанию — \Windows\ Minidumps.
2. Записывает имя файла минидампа в HKLM\Software\Microsoft\PCHealth\ ErrorReporting\KernelFaults.
3. Добавляет команду запуска утилиты Dumprep (\Windows\System32\Dump-rep.exe) в раздел HKLM\Software\Microsoft\Windows\CurrentVersion\Run, чтобы Dumprep запустилась при первом входе пользователя в систему.
Когда запускается утилита Dumprep (в результате того, что Savedump добавила в реестр соответствующее значение), эта утилита проверяет те же три параметра, что и Savedump, чтобы определить, должна ли система отправить отчет об ошибке после перезагрузки, вызванной крахом. Если должна, Dumprep генерирует XML-файл, содержащий базовое описание системы, в том числе версию операционной системы, список драйверов, установленных на компьютере, и список драйверов Plug and Play, загруженных в момент краха. Затем Dumprep выводит диалоговое окно, показанное на рис. 14-6, запрашивая у пользователя, нужно ли отправить в Microsoft отчет об ошибке. Если пользователь указал, что нужно, и это не противоречит групповым политикам, Dumprep отправляет XML-файл и минидамп на сайт
 |
Рис. 14-6.
Ферма серверов автоматического анализа использует тот же механизм, что и разработанные Microsoft отладчики ядра, в которые вы можете загрузить аварийный дамп (вскоре мы о них расскажем). При анализе генерируется так называемый
Если у организации нет доступа к Интернету или она не собирается автоматически отправлять аварийные дампы в Microsoft, то через групповые политики можно указать, что данные об ошибках должны храниться во внутреннем сетевом каталоге; в дальнейшем их можно будет обрабатывать с помощью Microsoft CER Toolkit, упоминавшегося выше.
Если при анализе, выполненном ОСА, не удалось найти решение проблемы или если вы не сумели отправить аварийный дамп на сайт OCA (например, если этот дамп сгенерирован Windows 2000, не поддерживающей ОСА), то вы можете самостоятельно проанализировать дамп. Как уже говорилось, когда вы загружаете аварийный дамп в Windbg или Kd, эти отладчики ядра применяют тот же механизм анализа, что и ОСА. Иногда даже базового анализа достаточно для выявления проблемы. Таким образом, если вам повезет, вы найдете решение проблемы путем автоматического анализа аварийного дампа. Ho даже если и не повезет, существуют простые методики выявления причин краха.
B этом разделе поясняется, как выполнить базовый анализ аварийного дампа, затем даются рекомендации, как с помощью Driver Verifier (с которым вы познакомились в главе 7) перехватывать операции некорректно написанных драйверов, приводящие к повреждению системы, и получать аварийные дампы, анализ которых может выявить проблему.
Различные виды краха системы, рассматриваемые здесь, можно вызвать с помощью утилиты Notmyfault
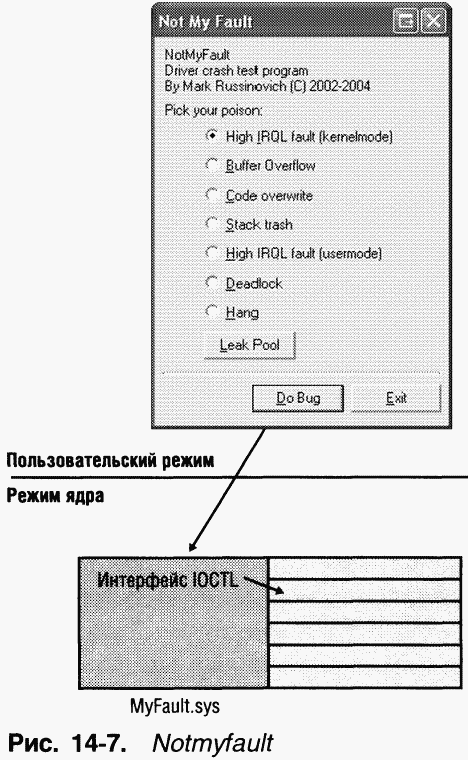 |
Самый простой для отладки крах вызывается при выборе переключателя High IRQL Fault (Kernelmode) и нажатии кнопки Do Bug. Тогда драйвер выделит страницу в пуле подкачиваемой памяти, освободит страницу, поднимет уровень IRQL выше «DPC/dispatch», а затем обратится к освобожденной странице. (Об IRQL см. главу 3.) Если это не приведет к краху, система продолжит считывать память после конца страницы до тех пор, пока не произойдет крах из-за обращения к недействительной странице. Таким образом, драйвер выполняет несколько недопустимых операций.
1. Ссылается на память, которая ему не принадлежит.
2. Обращается к пулу подкачиваемой памяти при IRQL уровня «DPC/dispatch» или выше, что недопустимо, так как при таких IRQL ошибки страниц не разрешены.
3. Выходит за конец выделенной области памяти и пытается обратиться к памяти, которая потенциально может быть недействительной. Первое обращение к странице не обязательно должно вызвать крах, если страница, освобожденная драйвером, остается в системном рабочем наборе. (O системном рабочем наборе см. главу 7.)
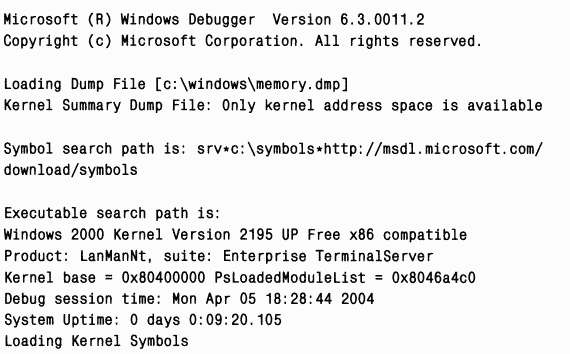
Загрузив в Kd аварийный дамп, сгенерированный при таком крахе, вы увидите следующие результаты:
 |
 |
Прежде всего следует заметить, что Kd сообщает об ошибках при загрузке символов для Myfault.sys и Notmyfault.exe. Этого можно было ожидать, поскольку файлы символов для них нельзя обнаружить по пути поиска файлов символов (который указывает на сервер символов Microsoft). Вы будете получать аналогичные ошибки для драйверов сторонних производителей и исполняемых файлов, не входящих в операционную систему.
Текст, содержащий результаты анализа, достаточно краток: показаны числовой стоп-код и контрольные параметры, далее идет строка «probably caused by». B ней указан драйвер, который, с точки зрения механизма анализа, является наиболее вероятной причиной ошибки. B данном случае наш драйвер попал на заметку, и эта строка указывает прямо на Myfault.sys, поэтому проводить анализ вручную нет нужды.
Строка «Followup», как правило, не несет полезной информации — эти данные используются в Microsoft, когда отладчик ищет имя модуля в файле Triage.ini, содержащемся в подкаталоге Triage установочного каталога Debugging Tools for Windows. B версии этого файла, используемой внутри Microsoft, перечислены разработчики или группы, которые должны анализировать крах системы, вызываемый тем или иным драйвером, и, если удалось найти разработчика или группу, соответствующее имя выводится в строке Followup.
Bo всех случаях, даже когда удалось выявить сбойный драйвер с помощью базового анализа аварийного дампа Notmyfault, нужно проводить детальный анализ командой:
Первое очевидное отличие детального анализа и анализа по умолчанию состоит в том, что в первом случае выводится описание стоп-кода и его параметров. Ниже приведен вывод этой команды для того же дампа:
 |
Таким образом, вам не придется открывать справочный файл, чтобы получить ту же информацию. Иногда выводимый текст содержит рекомендации по устранению неполадок — вы увидите такой пример в следующем разделе, где рассматривается углубленный анализ дампов.
Другая потенциально полезная информация, выводимая при детальном анализе — трассировочные данные стека потока, выполнявшегося в момент краха. Вот как она выглядит для того же дампа:
 |
Приведенный выше стек показывает, что образ исполняемого файла Not-myfaul, показанный внизу, вызывал функцию
Если вам не известен драйвер, выявленный при анализе, выполните команду
 |
Вы можете идентифицировать назначение драйвера по описанию, а также выяснить по версии файла и продукта, установлена ли у вас самая последняя версия. (Это можно определить, например, посетив сайт разработчика драйвера.) Если информация о версии отсутствует, например в момент краха соответствующая страница была выгружена из физической памяти, вы получите ее из свойств файла образа драйвера: просмотрите их с помощью Windows Explorer.
B предыдущем разделе, когда мы вызвали крах системы, выбрав параметр High IRQL Fault (Kernelmode) в Notmyfault, автоматический анализ дампа в отладчике не составил труда. Увы, в большинстве случаев исследовать крах системы с помощью отладчика сложно, а зачастую и невозможно. Существует несколько уровней верификации (с нарастающей степенью сложности и пропорциональным падением производительности системы), которые позволяют добиться того, чтобы вместо дампа, непригодного для анализа, генерировался дамп, пригодный для анализа. Если после настройки системы в соответствии с требованиями одного уровня и перезагрузки, вам не удалось выявить причину краха, попробуйте перейти на следующий уровень.
1. Если вы считаете, что крах системы может вызывать один или несколько драйверов, поскольку они были установлены в систему относительно недавно или их недавно обновили, или это следует из обстоятельств, при которых система терпит крах, то включите верификацию этих драйверов в Driver Verifier и выберите все режимы верификации, кроме имитации нехватки ресурсов.
2. Задайте тот же уровень верификации, но для всех неподписанных драйверов в системе. Или, если вы работаете с Windows 2000, в которой Driver Verifier не делает различий между подписанными и неподписанными драйверами, включите верификацию всех драйверов, поставляемых не Microsoft, а другими компаниями.
3. Задайте тот же уровень верификации, но для всех драйверов системы. Чтобы сохранить приемлемую производительность, можно разбить драйверы на группы и в промежутках между перезагрузками активизировать Driver Verifier для какой-то одной группы драйверов.
Очевидно, прежде чем тратить время и силы на изменение конфигурации системы и анализ аварийных дампов, стоит убедиться в том, что используются последние версии компонентов ядра и драйверов сторонних поставщиков, и при необходимости обновить их через Windows Update или напрямую через сайты производителей устройств.
B следующих разделах показывается, как с помощью Driver Verifier сделать так, чтобы вместо дампов, непригодных для отладки, создавались дампы, позволяющие решить проблему. Кроме того, почитайте справочный файл Debugging Tools, где есть руководства по методикам углубленной отладки.
Несомненно, что чаще всего причиной краха Windows является повреждение пула. Обычно оно вызывается ошибкой драйвера, в результате которой данные записываются до начала или за концом буфера, выделенного в пуле подкачиваемой или неподкачиваемой памяти. Структуры управления пулами (pool tracking structures) исполнительной системы располагаются с каждой стороны буфера и отделяют их друг от друга. Таким образом, подобные ошибки приводят к повреждению структур управления пулами, повреждению буферов других драйверов или и к тому, и к другому. Крах, вызванный повреждением пулов, практически невозможно исследовать с помощью отладчика, поскольку крах системы происходит при обращении к поврежденным данным, а не в момент их повреждения.
Вы можете вызвать крах, связанный с переполнением буфера, запустив Notmyfault и выбрав переключатель Buffer Overflow. B этом случае Myfault выделит память под буфер и перезапишет 40 байтов, идущих после буфера. Между щелчком кнопки Do Bug и крахом системы может пройти довольно много времени, возможно, вам даже придется задействовать пул, запустив какие-либо приложения. Это еще раз подчеркивает, что повреждение может не скоро привести к последствиям, влияющим на стабильность системы. Анализ аварийного дампа, полученного при такой ошибке, почти всегда показывает, что проблема связана с Ntoskrnl или каким-либо другим драйвером. И это демонстрирует бесполезность детального анализа при таком описании стоп-кода:
 |
B описании стоп-кода рекомендуется запустить Driver Verifier для каждого нового или подозрительного драйвера или активизировать особый пул с помощью Gflags. B обоих случаях преследуется одна и та же цель: выявить потенциальное повреждение в момент, когда оно происходит, и вызвать крах системы так, чтобы при автоматическом анализе удалось обнаружить драйвер, вызвавший повреждение.
Если в Driver Verifier включен режим особого пула, проверяемые драйверы используют специальный пул вместо пула подкачиваемой или неподкачиваемой памяти во всех случаях, когда выделяется память для буферов размера, немного меньшего размера страницы. Буфер, память под который выделяется из особого пула, заключен между двумя недействительными страницами и по умолчанию выравнивается по верхней границе страницы. Кроме того, подпрограммы управления особым пулом заполняют неиспользуемое пространство страницы, содержащей буфер, по случайному шаблону. Ha рис. 14-8 показано, как выделяется память из особого пула.
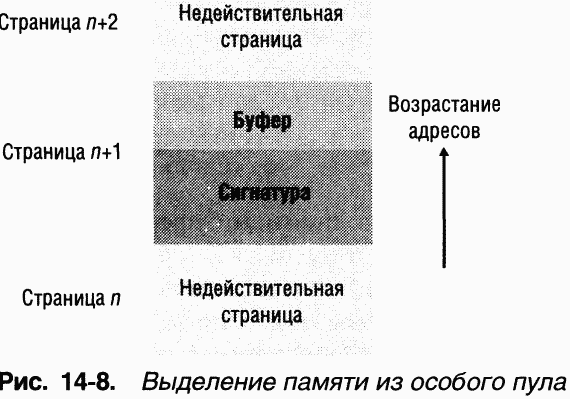 |
Система обнаруживает любые переполнения буфера, содержащегося в странице, поскольку они приводят к ошибке страницы: происходит обращение к недействительной странице, которая идет за буфером. Сигнатура нужна, чтобы перехватывать выход за конец буфера в момент, когда драйвер освобождает буфер: при выходе за конец будет нарушена целостность шаблона, помещенного в эту область при выделении памяти под буфер.
Чтобы посмотреть, как с помощью особого пула вызвать крах системы, который легко диагностировать с помощью механизма автоматического анализа, запустите DriverVerifier Manager (Диспетчер проверки драйверов). В Windows 2000 перейдите на вкладку Settings (Параметры), введите myfault.sys в текстовое поле внизу страницы, предназначенное для задания дополнительных драйверов, установите флажок особого пула, сохраните изменения, выйдите из Driver Verifier Manager и перезагрузитесь. B Windows XP и Windows Server 2003 выберите Create Custom Settings (For Code Developers) [Создать не стандартные параметры (для кода программ)] на первой странице мастера, на второй — Select Individual Settings From A Full List (Выбрать параметры из списка), на третьей — Special Pool (Особый пул). Далее выберите Select Drivers From A List (Выберите имя драйвера из списка), а на странице, где перечислены типы драйверов, введите myfault.sys в диалоговом окне, открываемом после нажатия кнопки добавления незагруженных драйверов. (He ищите в этом диалоговом окне файл myfault.sys — просто введите его имя.) Затем отметьте драйвер myfault.sys, выйдите из мастера и перезагрузитесь.
Когда вы запустите Notmyfault и вызовете переполнение буфера, сразу же произойдет крах системы, а анализ дампа даст следующий результат:
При детальном анализе вы получите следующее описание стоп-кода:
 |
Благодаря особому пулу трудноуловимая ошибка немедленно проявила себя, и анализ стал тривиальным.
Драйвер, в котором из-за «бага» происходит повреждение или неправильная интерпретация его собственных структур данных, может обращаться к не принадлежащей ему памяти, воспринимая поврежденные данные как указатель на область памяти. Такой некорректный указатель может указывать на что угодно в адресном пространстве, в том числе на данные, принадлежащие другим драйверам, недействительные страницы памяти или на код других драйверов или ядра. Как и при переполнении буфера, драйвер, вызвавший повреждение данных, обычно не удается идентифицировать в момент, когда повреждение обнаруживается и происходит крах системы. Использование особого пула увеличивает вероятность выявления «багов», связанных с некорректными указателями, но не выявляет повреждение кода.
Если вы запустите Notmyfault и выберете переключатель Code Overwrite, драйвер Myfault повредит точку входа функции
B описании стоп-кода, выводимом при детальном анализе, говорится, что драйвер Myfault попытался записать данные в память, доступную только для чтения:
 |
Однако, если у вас Windows 2000 и более 127 Мб памяти либо Windows XP или Windows Server 2003 и более 255 Мб памяти, произойдет крах другого типа, так как повреждение памяти сразу не проявится. Поскольку
 |
Разные конфигурации ведут себя по-разному в связи с тем, что в Windows 2000 введен механизм
 |
Если защита системного кода от записи включена, диспетчер памяти проецирует Ntoskrnl.exe, HAL и загрузочные драйверы как стандартные физические страницы (4 Кб для x86 и x64, 8 Кб для IA64). Поскольку при проецировании образов обеспечивается детализация с точностью до размера стандартной страницы, диспетчер памяти может защитить страницы, содержащие код, от записи и генерировать ошибку доступа при попытке их модификации (что вы и видели при первом крахе). Ho когда защита системного кода от записи отключена, диспетчер памяти использует при проецировании Ntoskrnl.exe большие страницы (4 Мб для x86 или 16 Мб для IA64 и x64). Taкой режим по умолчанию действует в Windows 2000 при наличии более чем 127 Мб памяти, а в Windows XP или Windows Server 2003 — при наличии более чем 255 Мб памяти. Диспетчер памяти не может защитить код, поскольку код и данные могут находиться на одной странице.
Если защита системного кода от записи отключена и при анализе аварийного дампа сообщается о маловероятных причинах краха или если вы подозреваете, что произошло повреждение кода, следует включить защиту. Для этого проще всего включить проверку хотя бы одного драйвера с помощью Driver Verifier. Кроме того, можно включить защиту вручную, добавив два параметра в раздел реестра HKLM\System\CurrentControlSet\Control\Session Manager\Memory Management. Сначала укажите максимально возможное значение для объема памяти, начиная с которого диспетчер памяти использует при проецировании Ntoskrnl.exe большие страницы вместо стандартных. Создайте параметр LargePageMinimum типа DWORD, присвойте ему значение 0xFFFFFFFF. Добавьте еще один параметр типа DWORD — Enforce-WriteProtection — и присвойте ему значение 1. Чтобы изменения вступили в силу, перезагрузите компьютер.
B предыдущем разделе рассказывалось о том, как с помощью Driver Verifier получать аварийные дампы, автоматический анализ которых может решить проблему. Тем не менее, возможны случаи, когда невозможно добиться, чтобы система сгенерировала дамп, который легко проанализировать. B таких случаях нужен анализ вручную, чтобы попытаться определить, в чем заключается проблема.
• C помощью команды отладчика
• C помощью команды
• C помощью команды
Существуют и другие отладочные команды, которые могут оказаться полезными, но для их применения нужны более глубокие знания. Одной из таких команд является
Переполнение или засорение стека (stack trashing) вызывается ошибками, связанными с выходом за конец или начало буфера. Однако в таких случаях буфер находится не в пуле, а в стеке потока, выполняющего ошибочный код. Ошибки этого типа также трудны в отладке, поскольку стек играет важную роль при любом анализе аварийного дампа.
Когда вы запускаете Notmyfault и выбираете Stack Trash, драйвер Myfault переполняет буфер, память под который выделена в стеке потока, где выполняется код драйвера. Myfault пытается вернуть управление вызвавшей его функции Ntoskrnl и считывает из стека адрес возврата, с которого должно продолжиться выполнение. Однако этот адрес поврежден при переполнении буфера стека, поэтому поток продолжает выполнение с какого-то другого адреса, может быть, даже не содержащего код. Когда поток попытается выполнить недопустимую инструкцию процессора или обратится к недопустимой области памяти, будет сгенерировано исключение и произойдет крах системы.
B различных случаях краха анализ аварийного дампа, проводимый при переполнении стека, будет указывать на разные драйверы, но стоп-код всегда будет одним и тем же — KMODE_EXCEPTION_NOT_HANDLED. Если вы выполните детальный (verbose) анализ, трассировочная информация для стека будет выглядеть так:
Это объясняется тем, что мы перезаписываем стек нулями. K сожалению, такие механизмы, как особый пул и защита системного кода от записи, не позволяют выявлять «баги» этого типа. Придется выполнять анализ вручную, по косвенным признакам определяя, какой драйвер выполнялся в момент повреждения стека. Один из возможных вариантов — исследовать IRP-паке-ты, с которыми работает поток, выполняемый в момент засорения стека. Когда поток передает запрос ввода-вывода, диспетчер ввода-вывода записывает указатель на соответствующий IRP в список Irp, хранящийся в структуре ETHREAD потока. Команда отладчика
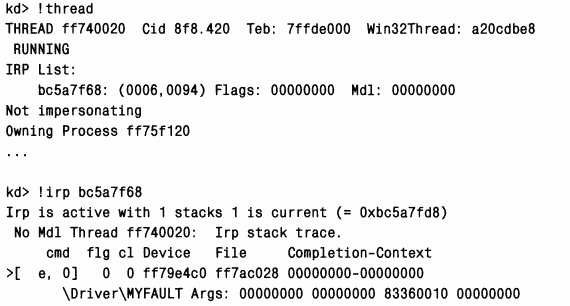 |
Вывод показывает, что текущий и единственный фрагмент стека для IRP (обозначенный префиксом «›») принадлежит драйверу Myfault. Если бы это было на практике, далее следовало бы убедиться, что установлена последняя версия драйвера, и, если это не так, установить новую версию. Если это не помогло, нужно было бы активизировать Driver Verifier для данного драйвера (включив все режимы, кроме имитации нехватки памяти).
Если система перестает отвечать (т. е. не реагирует на ввод с клавиатуры или мыши, курсор мыши не перемещается или вы можете перемещать курсор, но система не реагирует на щелчки), говорят, что система
• при обращении к драйверу устройства ISR (interrupt service routine) или DPC не вернула управление;
• поток с высоким приоритетом (выполняемый в режиме реального времени) вытеснил потоки ввода данных в подсистему управления окнами (windowing system);
• произошла взаимная блокировка при выполнении кода в режиме ядра (два потока или процессора удерживают ресурсы, нужные друг другу, причем ни один из них не освобождает свой ресурс).
Если вы работаете с Windows XP или Windows Server 2003, то можете выявлять взаимные блокировки, используя одну из функций Driver Verifier — обнаружение взаимных блокировок (deadlock detection). При обнаружении взаимных блокировок ведется наблюдение за спин-блокировками (spin locks), быстрыми и обычными мьютексами и выявляются закономерности, которые могут приводить к взаимной блокировке. (Информацию об этих и других синхронизирующих примитивах см. в главе 3.) Если обнаружена такая ситуация, Driver Verifier вызывает крах системы, указывая, какой драйвер является причиной взаимной блокировки. Простейшая форма взаимной блокировки — каждый из двух потоков удерживает некий ресурс, нужный другому потоку, при этом ни один из них не освобождает свой ресурс и ждет освобождения другого ресурса. Если вы используете Windows XP или Windows Server 2003, первое, что нужно сделать для устранения зависаний системы, — включить обнаружение взаимных блокировок для подозрительных драйверов, затем для неподписанных драйверов, а затем для всех драйверов. B этом режиме следует работать до тех пор, пока не произойдет крах системы, который позволит выявить драйвер, вызывающий взаимную блокировку.
Если вы используете Windows 2000 или если вы проверили все драйверы, а система продолжает зависать, то должны либо вручную вызвать крах зависшей системы и проанализировать полученный в результате дамп, либо исследовать систему с помощью отладчика ядра.
Итак, есть два подхода к исследованию зависающей системы, позволяющие выявить драйвер или компонент, который вызывает зависания. Первый — вызвать крах зависшей системы и надеяться, что будет получен дамп, который удастся проанализировать. Второй — исследовать систему с помощью отладчика ядра и проанализировать работу системы. И при том, и при другом подходе необходимы предварительная настройка и перезагрузка. Чтобы выявить и устранить причину зависания, в обоих случаях выполняется одно и то же исследование состояния системы.
Чтобы вручную вызвать крах зависшей системы, сначала добавьте в реестр параметр HKLM\System\CurrentControlSet\Services\i8042prt\Parameters\ CrashOnCtrlScroll типа DWORD со значением 1. После перезагрузки порт-драйвер i8042, который является драйвером порта ввода с PS/2-клавиатуры, будет наблюдать за нажатиями клавиш в своей ISR (об ISR подробно рассказывается в главе 3) и отслеживать двукратное нажатие клавиши Scroll Lock при нажатой правой клавише Ctrl. Обнаружив такую последовательность нажатий, драйвер вызывает функцию
Еще один способ вручную вызвать крах системы — использовать встроенную кнопку «crash». (Она имеется на некоторых серверах класса «high end».) Тогда, чтобы инициировать крах, материнская плата системы генерирует NMI (немаскируемое прерывание). Чтобы активизировать эту функцию, задайте значение 1 для содержащегося в реестре DWORD-параметра HKLM\ System\CurrentControlSet\Control\CrashControl\NMICrashDump. B этом случае при нажатии кнопки «crash» в системе будет генерироваться NMI, и обработчик NMI-прерываний ядра вызовет
Если сгенерировать аварийный дамп вручную нельзя, попытайтесь исследовать зависшую систему. Прежде всего загрузите систему в отладочном режиме. Это можно сделать двумя способами. Нажмите клавишу F8 во время загрузки и выберите Debugging Mode (Режим отладки) или добавьте запись, задающую загрузку в отладочном режиме, в файл Boot.ini: скопируйте запись, которая уже имеется в файле Boot.ini системы, и добавьте ключ /DEBUG. При нажатии F8 система будет использовать соединение по умолчанию (последовательный порт COM2 и скорость 19200 бод). При использовании режима /DEBUG вы должны будете настроить механизм соединения между хост-системой, на которой выполняется отладчик ядра, и целевой системой, загружаемой в отладочном режиме, и задать ключи /Debugport и /Baudrate, соответствующие типу соединения. Доступно два типа соединения: нуль-модемный кабель, соединяющий последовательные порты, или (в системах Windows XP и Windows Server 2003) кабель IEEE 1394 (Firewire), подключенный к порту 1394 каждой системы. Подробности настройки хост-системы и целевой системы для отладки ядра см. в справочном файле Windows Debugging Tools.
При загрузке в отладочном режиме система загружает отладчик ядра и готовит его к соединению с отладчиком ядра, выполняемом на другом компьютере, подключенном по нуль-модемному кабелю или по IEEE 1394. Заметьте: присутствие отладчика ядра не влияет на производительность. Когда система зависнет, запустите отладчик Windbg или Kd на подключенной системе, установите соединение между отладчиками ядра и выполните отладку кода зависшей системы. Такой подход не сработает, если прерывания отключены или если поврежден код отладчика ядра.
При выполнении анализа можно не оставлять систему в остановленном состоянии, а с помощью команды отладчика
Зависание можно вызвать, запустив Notmyfault и выбрав параметр Hang. Тогда драйвер Myfault поставит в очередь DPC, выполняющую бесконечный цикл для каждого процессора системы. Поскольку при выполнении DPC-функ-ций IRQL процессора имеет уровень «DPC/dispatch», ISR клавиатуры будет реагировать на последовательность нажатий клавиш, вызывающую крах.
Когда вы приступили к отладке зависшей системы или загрузили в отладчик дамп, который вручную сгенерировали для зависшей системы, следует выполнить команду
Если команда
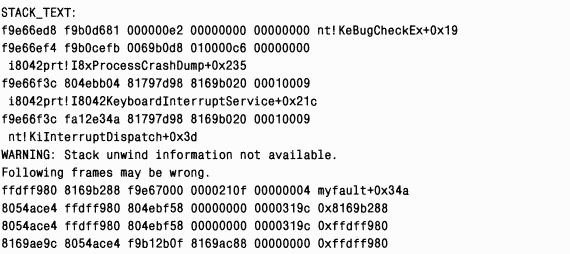 |
Первые несколько строк трассировочной информации стека относятся к подпрограммам, вызванным, когда вы нажали клавиши, по которым порт-драйвер i8042 вызывает крах системы. Присутствие драйвера Myfault означает, что зависание системы могло произойти из-за него.
Еще одна команда, которая может оказаться полезной, —
B этом разделе мы рассмотрим, как устранять неполадки в системах, которые по каким-либо причинам не записывают аварийный дамп. Аварийный дамп может не записываться из-за того, что размер страничного файла на загрузочном томе слишком мал, чтобы вместить дамп, или из-за того, что на диске недостаточно места, чтобы извлечь дамп после перезагрузки. Эти две причины легко устранить, увеличив размер страничного файла или задав при настройке, что дамп сохраняется на томе, где достаточно места.
Третьей причиной, по которой аварийный дамп не записывается, может быть то, что код ядра и структуры данных, необходимые для записи аварийного дампа, повреждены при крахе. Как уже говорилось, для этих данных подсчитывается контрольная сумма, и, если при крахе обнаружено несовпадение контрольных сумм, система даже не пытается сохранить аварийный дамп (чтобы не рисковать данными на диске). Поэтому в таком случае нужно отслеживать момент краха системы и пытаться определить причину краха.
Наконец, еще одна причина в том, что дисковая подсистема не может обрабатывать запросы записи на диск (ситуация, которая сама по себе может вызвать сбой системы). Такая ситуация возникает, если произошел аппаратный сбой контроллера дисков или поврежден кабель жесткого диска.
Одно из простых решений — отключить параметр Automatically Restart (Выполнить автоматическую перезагрузку) в параметрах Startup And Recovery (Загрузка и восстановление), чтобы можно было изучать «синий экран» с консоли. Однако текст «синего экрана» позволяет выявить причины краха системы только в самых простых случаях.
Для более глубокого анализа необходимо с помощью отладчика ядра исследовать поведение системы в момент краха. Для этого загрузите систему в отладочном режиме, о котором рассказывалось в предыдущем разделе. Когда происходит крах системы, загруженной в отладочном режиме, она не выводит «синий экран» и не пытается записать дамп, а ожидает соединения с отладчиком ядра, выполняемым на хост-системе. Поэтому можно увидеть, что вызвало причину краха, и, вполне вероятно, провести некий базовый анализ с помощью команд отладчика ядра, описанных ранее. Как говорилось в предыдущем разделе, команда отладчика позволяет сохранить копию памяти системы, потерпевшей крах, для дальнейшей отладки, что даст возможность перезагрузить эту систему и вести отладку в автономном режиме.
ЭКСПЕРИМЕНТ: экранная заставка Blue Screen
Отличный способ вспомнить, как выглядит «синий экран», или подшутить над своими друзьями и коллегами — запустить экранную заставку Sysinternals Blue Screen, которую можно скачать с сайта
C помощью утилиты Psexec с сайта Sysinternals вы даже можете запустить экранную заставку на другой системе, выполнив команду:
psexec \\computername — i — d "c: \sysinternals bluescreen.scr" — s
Для этого у вас должны быть административные привилегии на удаленной системе. (C помощью ключей
| © 2024 Библиотека RealLib.org (support [a t] reallib.org) |