"Журнал «Компьютерра» № 13 от 04 апреля 2006 года" - читать интересную книгу автора (Компьютерра)
ТЕМА НОМЕРА: Персональный суперкомпьютер
К тому, что современные игры не могут обойтись одним лишь центральным процессором (Central Processing Unit, CPU [CPU — central processing unit]), без поддержки видеокарты, мы привыкли настолько, что это считается само собой разумеющимся. Сегодня никого не удивляет анонс очередного графического чипа (Graphics Processing Unit, GPU [GPU — graphics processing unit]) производительностью несколько сотен гигафлопс[gflops — миллиард арифметических операций с действительными числами в секунду]. А ведь самые дорогие CPU, даже серверные, едва ли могут похвастаться и десятой долей этой числодробильной мощности. Как образовался такой колоссальный разрыв в скорости счета? Почему главная роль в компьютере, роль «мозга», по-прежнему остается за CPU, тогда как GPU не простаивает только во время кровавых игрищ? Что мешает задействовать GPU в «мирных» целях, превратить его в настоящий комбайн, выполняющий огромное количество задач, отличных от рендеринга, и ведется ли какая-нибудь работа в этом направлении?
Чтобы обстоятельно ответить на эти и другие вопросы, нам необходимо вспомнить основы устройства графической подсистемы. Ее работа организуется в форме конвейера, упрощенно представленного на рис. 1. Информация проходит все стадии конвейера, прежде чем преображается в видимый на экране образ.
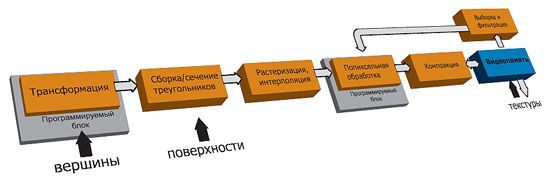 |
В самом начале располагается блок обработки вершин трехмерной сцены, целью которого является выработка данных о каждой вершине: ее положение в экранной системе координат, пара цветов (диффузный и зеркальный), до восьми текстурных координат. Следует напомнить, что текстурными называют координаты на отдельно хранящемся растровом изображении (текстуре). Их задание в каждой вершине треугольника позволяет привязать нужную часть изображения к этому треугольнику. Входные данные отдельно для каждой вершины поступают от программного приложения. Как правило, передаются координаты и нормали вершин в системе модели, которые по известным характеристикам, положению и направлению взгляда камеры трансформируются в экранные координаты. Цвета определяются взаимным расположением вершины, камеры и источников освещения. Отсюда и принятое название: блок трансформации и освещения (Tamp;L). Обработка вершин происходит независимо, здесь система еще не знает, как они связаны между собой.
Информация о том, какие тройки вершин образуют треугольники, поступает только на следующий этап конвейера, носящий название «сборка треугольников» (triangle setup). После этого уже можно определить, какие треугольники будут не видны на экране. Независимым исследованием вершин этого установить нельзя: три выходящие за границы экрана вершины могут сформировать частично видимый треугольник. Полностью скрытые треугольники удаляются, чтобы больше не отнимать на себя ресурсов. От частично видимых треугольников отсекаются ненужные части.
На этапе растеризации треугольники разбиваются на множество фрагментов, каждый из которых соответствует одному пикселу экрана, накрываемому треугольником. Здесь же происходит еще одна важная операция — линейная интерполяция значений из вершин треугольника в соответствии с положением фрагмента. После этого обработка каждого фрагмента может происходить автономно от других фрагментов.
В конечном результате для каждого фрагмента необходимо определить его итоговый цвет и, возможно, изменившуюся глубину. Для чего часто требуется доступ к хранящимся в видеопамяти текстурам, которые могут содержать как непосредственно цвет, так и освещенность, отражательную способность или карту неровностей. Доступ к текстурам осуществляется через блок выборки (fetch), который может вернуть цвет текстуры в произвольной точке, а также может выполнять билинейную или анизотропную фильтрацию.
О фрагментах следует думать как о пре-пикселах. Окончательное значение цвета на экране формируется в результате композиции цвета фрагмента с цветом, уже находящимся в экранном буфере, только частным случаем которой является полное замещение. Фрагмент на этом этапе может быть вообще отвергнут, если не пройдет один из тестов, например тест глубины или величины альфа-канала.
Свое окончание конвейер находит в экранном буфере или текстуре, его заменяющей, при включении специального режима render-to-texture. Это единственное место в конвейере, которое доступно приложению для обратного считывания (read back).
Как же использовать графический конвейер не только для отображения трехмерных сцен? Еще относительно недавно нужно было обладать незаурядными знаниями всех операций, которые производители «зашили» в графический чип, чтобы заметить задачу, сводимую к рисованию некоторой сцены. В любом случае, способностей GPU хватало лишь на очень узкий круг вычислительных проблем[Не хочется задерживаться на этой теме, но чтобы не быть голословным, привожу одну из ссылок, где есть программа построения диаграммы Вороного], как правило, не слишком требовательных к точности результата. Но с наступлением нового тысячелетия ситуация начала мало-помалу меняться.
Прежде программирование графики можно было отнести к декларативному типу. Трехмерное приложение перечисляло все объекты в сцене, свойства их поверхностей, говорило, где расположены источники освещения, куда смотрит камера и т. п. В завершение следовала команда графической плате: «А теперь возьми и отобрази, что видит камера!» Эта ситуация была бы всем хороша в спокойные времена, но не когда производители игр отчаянно борются за внимание пользователей, которое, по их мнению, можно привлечь только новыми и желательно уникальными эффектами. Поэтому наметился постепенный переход к императивной парадигме программирования графики. То есть вместо выбора одного из предопределенных типов обработки данных производители игр получили возможность самостоятельно писать малюсенькие программки, непосредственно выполняемые графическим процессором. В первую очередь это затронуло блок обработки вершин, а затем и фрагментов (обведены оранжевым цветом на рис. 1). Поскольку главным образом под эффектами понималась более точная передача игры света и тени, то программки эти стали называть шейдерами (от англ. shade — тень), соответственно разделяя их на вершинные и пиксельные. Появились специализированные низкоуровневые ассемблеры.
Поначалу (2001 год) шейдеры были сильно ограничены в функциональности: например, пиксельный шейдер мог считывать цвет точки текстуры только четыре раза и выполнять над этими цветами не больше восьми арифметических операций[Хотя малым это стало казаться только сейчас, а на момент появления впечатляло].
Переломным моментом можно считать самый конец 2002 года, когда в продаже появились платы семейства GeForce FX от nVidia и Radeon 9500 (и выше) от ATI. В них была заложена поддержка стандарта шейдеров Shader Model 2.0, который примечателен главным образом двумя аспектами.
Стандарт требовал от GPU умения выполнять гораздо более сложные программы и по количеству инструкций, и по числу обращений к текстурам.
Все промежуточные операции должны были выполняться с действительными числами высокой (в сравнении с предшествующими моделями GPU) точности. А производители сразу ввели поддержку текстур, в которых цвета хранятся также в виде действительных чисел.
Хотя позже появляются и другие модификации стандарта, включая последний на сегодняшний день Shader Model 3.0, шейдеры второй версии остаются по-прежнему актуальными, потому что платы, поддерживающие только их, присутствуют на рынке и сегодня. Особенности стандартов приведены в таблице 1.
 |
Как только число инструкций в программе достигло десятков, пользоваться ассемблером стало не так удобно. Поэтому к тому же времени формируются специализированные C-подобные языки высокого уровня. Заслуживают упоминания как минимум три из них: cg от nVidia, HLSL из DirectX и GLSL из OpenGL. Все они очень похожи, но, к сожалению, отличаются лексическими и синтаксическими деталями. Их компиляторы к сегодняшнему дню стали довольно зрелыми, способны оптимизировать код, хотя небольшая вероятность наткнуться на неправильно скомпилированный шейдер еще остается. Отказываться от высокоуровневых языков сейчас приходится лишь в исключительных случаях, например, чтобы уложиться в лимит регистров или инструкций.
Достоинства графических чипов: высокая производительность, точность и достаточная простота программирования не могли не быть замеченными, в первую очередь университетами. В 2003 году наблюдается всплеск научных статей, посвященных алгоритмам и принципам расчетов общего назначения средствами графических плат (GPGPU[GPGPU — General-Purpose Computation on GPUs]). С 2004 года специально организуются научные конференции.
В этой связи любопытно поведение двух крупнейших игроков на рынке графических чипов. Если aTI, по-видимому, заняла выжидательную, консервативную позицию: «GPU нужен только для игр», то nVidia, наоборот, проявляет заметную активность. Она пропагандирует идею GPGPU, организует курсы, призывая исследователей пользоваться ее аппаратурой для неграфических вычислений[gpgpu.org/s2005], предоставляет им временную или постоянную работу. Под эгидой nVidia издано уже два бестселлера «GPU Gems»[developer.nvidia.com/object, developer.nvidia.com/object/gpu_gems_2_home.html], в которые вошли главы по вычислениям общего назначения. С 2002 года сотрудники фирмы ведут сайт gpgpu.org, пытающийся систематизировать все результаты в этой области. nVidia продает ряд продуктов для нужд киноиндустрии, на деле доказывая нешуточность идеи.
Каковы результаты этой активности? Судя по публикациям, GPU удается найти применение в самых различных областях высокопроизводительных вычислений, включая высококачественный рендеринг, трассировку лучей, обработку изображений и сигналов, машинное зрение, компрессию, поиск и сортировку, биоинформатику, решение систем линейных уравнений, моделирование физических эффектов. Достигаемое ускорение колеблется от случая к случаю, но типично составляет несколько крат по сравнению с расчетом на центральном процессоре. Вы спросите, отчего же CPU так катастрофически проигрывают, если они изготовляются на таких же, если не на лучших полупроводниковых фабриках, содержат сопоставимое число транзисторов[Буквально одно сравнение high-end-продуктов в подтверждение: 376 млн. транзисторов в двухъядерном Intel Pentium EE 955 против 384 млн. в ATI Radeon X1900XTX], а их рабочие частоты в разы выше, чем у GPU?
Одно арифметическое устройство, оперирующее числами с плавающей точкой, при современном технологическом процессе производства чипов занимает на кристалле меньше одного квадратного миллиметра[Эти и последующие числа раздела взяты из книги «GPU Gems 2»]. Поэтому во всем чипе их можно иметь сотни, но проблема не в количестве устройств, а в том, как их все загрузить работой. К сожалению, на этом пути есть препятствия.
В первую очередь — память. По закону Мура, каждый год количество транзисторов на чипе возрастает наполовину, возрастает (но медленнее) и скорость их работы, так что суммарно можно говорить примерно о семидесятипроцентном повышении теоретической производительности устройств. Почему теоретической? Да потому, что пропускная способность памяти ежегодно возрастает примерно на 25%, а ее латентность (задержка обращения к новому участку памяти) сокращается и того медленнее — всего на 5% в год. Поэтому если не предпринимать дополнительных усилий, то самое слабое звено и будет определять производительность всей системы.
Центральный процессор обеспечивает просто райские условия для разработчика: любая инструкция в программе может считать или записать произвольную ячейку большой оперативной памяти. На деле это выливается в совершенно нерегулярный набор обращений к памяти. И чтобы ее латентность не была столь критической, в процессор приходится встраивать быструю кэш-память. И встраивать много — кэш сейчас занимает не меньше половины площади кристалла, а значит, ее не занимают вычислительные блоки. Причем во многих сценариях большой кэш оказывается неэффективен, к примеру, если обращение к ячейке памяти происходит лишь единожды, как при обработке потоков.
Второй важной причиной является последовательный характер обычных программ — наборов инструкций, которые для получения желаемого результата должны выполняться друг за другом. Если одна инструкция задержится медленной памятью, то задержится исполнение и всех остальных. Конечно, не все инструкции являются зависимыми и поэтому могут выполняться одновременно. Но явно эта независимость в программе не отражена, так что на выявление скрытого параллелизма тратится другая заметная порция площади кристалла. В самом лучшем случае удается наскрести работу для считанных единиц исполнительных устройств.
 |
Как же эти проблемы решаются в GPU? При описании графического конвейера неоднократно подчеркивалось, что внутри каждого блока конвейера выполняются независимые действия: вершины обрабатываются независимо одна от другой, аналогичное утверждение справедливо для треугольников и т. д. Поэтому не только отдельные этапы конвейера функционируют одновременно, но и на каждом этапе идет параллельная обработка. В этом смысле внутри GPU выделяются наборы вершинных и пиксельных процессоров (рис. 2). Для обеспечения произвольного порядка обработки фрагментов текстура, в которую выполняется рисование, не может в то же самое время использоваться и для выборки, то есть видеопамять делится на непересекающиеся участки только-для-чтения и только-для-записи. Также не могут совпадать обновляемые точки в целевой структуре, поскольку итоговое положение каждого фрагмента фиксируется еще на этапе растеризации. Этими ограничениями достигается достаточное свойство параллельности пиксельных процессоров. Теперь, несмотря на то что каждый шейдер — это последовательная программа, при задержке обращения к памяти при обработке одного фрагмента GPU может не простаивать, а переключиться на другой фрагмент — кандидатов всегда достаточно. Имеются и элементы явного параллелизма в шейдерах: каждая ассемблерная инструкция может выполнять операцию не со скалярами, а сразу с четырехэлементными векторами[Число четыре возникло не случайно — именно такова размерность гомогенного пространства, и таково число компонентов в полупрозрачной цветной текстуре. Векторными операциями можно не пользоваться, но тогда эффективность GPU резко снижается], есть комбинированная инструкция умножь-затем-прибавь.
Без ячеек памяти, которые можно и считывать, и записывать, совсем обойтись, конечно, нельзя. Каждому шейдеру для этой цели предоставляются регистры, их мало (табл. 1), приходится экономить, но благодаря этому все промежуточные вычисления ведутся без обращения к внешней памяти, куда попадает лишь финальный результат. Малый размер шейдера и его общность для всех фрагментов преследуют ту же цель — хранить код программы не в памяти, а внутри процессора. Ведется последовательная политика, включающая разъяснительные мероприятия среди разработчиков, увеличения количества арифметических операций между последовательными обращениями к памяти.
Во всем конвейере главными претендентами для выполнения неграфических расчетов, безусловно, являются вершинные и пиксельные процессоры. Рассмотрим для примера плату GeForce 6800 Ultra. В ней имеется шесть вершинных процессоров, каждый из которых способен за такт выполнять максимум две арифметические операции над четырехэлементными векторами, а также шестнадцать пиксельных процессоров, способных на три векторные операции за такт. Умножая на частоту чипа 425 МГц, получаем верхнюю оценку производительности в 100 Гфлопс. Проделав те же выкладки для новейшей GeForce 7900 GTX, имеющей уже восемь вершинных и двадцать четыре пиксельных процессора и функционирующей на частоте 650 МГц, получаем почти 230 Гфлопс.
Можно задействовать и другие участки конвейера. Если в пиксельном шейдере нужно вычислять некоторую линейную[Есть еще сферические и кубические текстуры, но их ценность для целей данной статьи сомнительна] функцию координаты, то можно перенести эту работу на этап растеризации, задав значения функции только в углах треугольника.
На этапе композиции можно выполнять условные присваивания, вычислять линейную комбинацию векторов, так же как и на этапе фильтрации. Однако эти действия не поддерживаются всеми современными платами для интересующих нас чисел высокой точности. Но если вас устроит «половинная» точность (16 бит), то оценка производительности может быть поднята еще выше.
Вы должны понимать, что это крайне оптимистичные оценки, реально достижимая скорость счета заметно ниже. На практике не всегда удается задействовать даже вершинные процессоры. Дело в том, что до Shader Model 3.0 они были лишены доступа к текстурам, то есть к памяти. К тому же их вывод не записывает в память непосредственно, а лишь определяет области, которые будут обсчитаны пиксельными процессорами. Конечно, и этим можно умело пользоваться, чтобы уменьшить размер и повысить скорость пиксельных шейдеров, но трудоемкость разработки всей программы для GPU сильно возрастает. Впрочем, здесь тоже ожидается скорый прогресс — уже вовсю говорят об унифицированных шейдерных процессорах, способных выполнять обработку как вершин, так и пикселов и не простаивать при любом виде нагрузки.
Для совершения первых шагов в освоении сопроцессора GPU начинающий разработчик должен научиться переводить графические термины на более привычный ему компьютерный язык.
Самое главное — понимание организации памяти. Универсальной встроенной структурой данных в GPU является текстура. Текстуры бывают одномерные, двухмерные и трехмерные[Т. Кормен, Ч. Лейзерсон, Р. Ривест. Алгоритмы. Построение и анализ. — М.: МЦНМО, 2000]. Это прямой аналог многомерному массиву. Пиксел текстуры (тексел) -элемент массива. К сожалению, максимальные ширина, высота и глубина текстуры строго ограничены. Этот предел зависит от платы и от размерности и обычно равен 2048 или 4096. Поэтому одномерные текстуры становятся малоинтересными — в них вмещается слишком мало данных. Трехмерные текстуры отпадают по другой причине — они могут быть только считаны, но рисование в них невозможно. Остаются только двухмерные текстуры, в которые нужно научиться упаковывать все прочие структуры данных. Заметим, что эффективная размерность всех текстур на единицу больше, поскольку каждый тексел может содержать до четырех цветовых компонентов. Например, длинный одномерный массив можно упаковать таким образом: первые четыре элемента записываются в тексел на пересечении первой строки и первого столбца, следующие четыре — в тексел из второго столбца и так до исчерпания первой строки, затем всё продолжается со следующей строки и т. д.
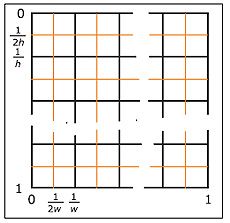 |
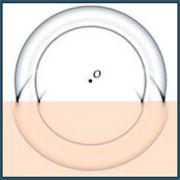
Любопытна система адресации в текстуре, которая осуществляется заданием по каждой координате действительного числа из диапазона [0,1]. Расстояние (изменение индекса при переходе) между соседними текселами уже не 1, как в обычном массиве, а зависит от разрешения текстуры (рис. 3). Для получения точного значения тексела необходимо указать координаты центра его «квадратика», при запросе по другому адресу результат будет зависеть от текущего режима фильтрации.
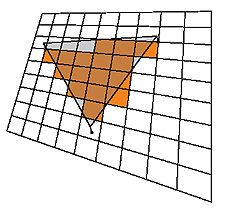 |
Запись данных в текстуру достигается назначением ее в качестве цели рендеринга (render target). Последующее рисование какой-либо фигуры фактически выбирает обновляемые элементы текстуры (рис. 4). Обычно рисуют один большой треугольник, покрывающий цель рендеринга с запасом, либо прямоугольник точно совпадающих размеров. Неудобно то, что координаты углов фигур нужно задавать уже не в текстурных, а в отличающихся от них экранных (viewport) координатах. Итак, координаты вершины определяют рассчитываемые фрагменты. Входные аргументы пиксельному шейдеру передаются через ассоциированные с вершиной данные, в первую очередь через текстурные координаты.
Процедура обработки одинакова для всех пикселов. Поэтому о пиксельном шейдере можно думать как о теле некоторого цикла. Также можно, рисуя меньшие фигуры и «играя» с тестом глубины, применять различные шейдеры избирательно. Такая необходимость возникает, когда алгоритмы обработки внутренних и приграничных точек текстуры существенно отличаются и их невозможно или нецелесообразно совмещать в одном шейдере.
Сейчас мы уже знаем, что GPU способен применять одинаковую программу для вычисления значения каждого элемента одного массива, основываясь на данных других массивов. Есть ли алгоритмы, которые формулируются именно таким образом? Оказывается, есть. К этому классу относятся, например, методы фильтрации изображений и часть способов приближенного решения дифференциальных уравнений, отражающих динамические явления физики. Именно такие алгоритмы проще всего переносятся на GPU, и именно на них достигается наибольшее ускорение.
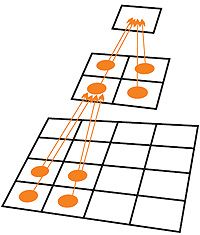
Давайте рассмотрим что-нибудь посложнее. Задача редукции массива заключается в нахождении какой-то скалярной функции его элементов. Это может быть сумма всех чисел массива, или величина максимума, или что-то в том же духе. Поскольку шейдер ограничен в количестве операций, за один проход рендеринга решить задачу решительно невозможно. Применяется следующий способ. Порождается вспомогательная текстура, размерами чаще всего вдвое меньше исходной по обеим осям. Используемый шейдер, заполняя ее, вычисляет функцию только от четырех величин. Затем вспомогательная текстура назначается на вход шейдера, а выходом служит еще вчетверо меньшая текстура. И так до получения текстуры из одного пиксела, которая содержит ответ (рис. 5). Число проходов составляет логарифм от начального размера массива.
Умножить матрицу на вектор при ограничениях Shader Model 2.0 тоже не так-то просто. Одно из определений гласит, что произведение является линейной комбинацией столбцов исходной матрицы, взятых с весами из второго сомножителя. Поступают таким образом. На первом шаге каждый элемент матрицы умножается на соответствующий ему вес — получается вторая матрица. Последующие шаги посвящаются комбинированию столбцов — редукции только по горизонтали.
Еще интереснее дела обстоят с сортировкой массива. Сразу понятно, что в случае с GPU понадобится второй вспомогательный массив из-за невозможности выполнять чтение и запись одновременно с одним массивом. Но на этом сложности не кончаются. Алгоритмы сортировки основываются на операции сравнить-и-обменять: для выбранных двух позиций в массиве производится сравнение элементов, и, если они нарушают порядок сортировки, происходит их обмен. В GPU, как мы помним, определение новых значений массива выполняется независимо, поэтому каждое сравнение приходится делать дважды. Но и это еще не все. Выбор позиций для очередной операции сравнить-и-обменять в быстрых последовательных алгоритмах зависит от результата сравнения в предыдущих операциях. К счастью, в теории параллельных вычислений уже разработана тема сортирующих сетей, которую можно адаптировать для GPU. Количество операций, выполняемых параллельным алгоритмом, больше, чем у лучших последовательных алгоритмов, и их отношение растет с ростом массива. Тем не менее, благодаря своей мощи, современные GPU не уступают в скорости сортировки, хотя о существенном ускорении речь пока не идет.
 |
Остальные алгоритмы конвертируются как-то аналогично или строятся на основе приведенных. Труднее всего GPU даются сложные структуры данных: списки и деревья, особенно их модификация. Поверьте (а если не хотите верить — пройдитесь по ссылкам сами), что придумано множество других любопытных способов переноса, казалось бы, неподходящих расчетов на GPU, включая, например, работу с разреженными матрицами. Но они уже выходят за рамки популярной статьи.
Заметьте, что в последних трех примерах достижение результата на GPU потребовало использования большего объема памяти, чем понадобилось бы на машине классической архитектуры. Добавьте к этому более высокую производительность GPU, выливающуюся в потенциальную способность перемалывать бОльшие объемы данных, и вы поймете, почему размер видеопамяти так высоко ценится среди расчетчиков. В этом вопросе проступает болезненное расхождение с другими пользователями, которые твердо знают, что для компьютерных игр памяти на графической плате много не надо.
Если говорить о ближайшем будущем самих чипов, то здесь все замечательно. Год за годом GPU прибавляют в скорости работы куда быстрее, чем CPU, увеличивая и без того немалый отрыв. Поколения графических чипов тоже сменяются куда чаще. Даже для непрофессионального использования уже некоторое время предлагается устанавливать в компьютер две видеокарты (технологии SLI или Crossfire). Можно будет использовать вторую плату исключительно как сопроцессор для расчетов, полностью освободив ее от обработки графики. Радужные перспективы GPGPU способны поблекнуть только из-за недостаточной программной поддержки.
Неспособность центрального процессора в одиночку справляться с возникающими вычислительными задачами — секрет Полишинеля. Раньше всего это стало очевидно в машинной графике. В результате за прошедшие годы сформировался стандартный современный графический сопроцессор GPU. Сейчас речь заходит о создании других аппаратных акселераторов, в том числе и для игровых целей [Например, скоро вы можете столкнуться с невозможностью запустить игру без еще одного, на сей раз физического процессора:www.ageia.com/products/physx.html]. Но под каждое приложение свою «железку» не выпустишь, куда как интереснее увидеть нераскрытые возможности GPU, находящегося внутри почти каждого персонального компьютера.
Самое чудное во всей этой истории то, что GPU — а по сути суперкомпьютер на чипе — стал массовым продуктом не благодаря целенаправленной и продуманной стратегии ученых мужей, а скорее случайно — как побочное явление индустрии развлечений.
Одно дело — лицезреть графики ускорения на страницах чужих статей, и совсем другое — убедиться в этом самостоятельно. Не случайно ведь пользуются широкой популярностью такие тесты, как 3DMark и Doom 3. Ничего подобного им по удобству и авторитетности в области вычислений на GPU пока не существует. Можно упомянуть разве что пакет GPUBench из Стэнфордского университета, но он предназначен для сравнения GPU только между собой и содержит лишь синтетические тесты вроде скорости выполнения одной инструкции, повторенной многократно. Более того, далеко не каждую найденную программу для GPU вообще удается запустить из-за ориентации ее авторов на конкретного производителя[Если вы читали статью сначала, то легко угадаете какого. К сожалению, неполная совместимость GPU еще не изжита окончательно] графических чипов. Поэтому я решил подойти к проблеме творчески и предложить самодельный набор тестов [Исходные тексты и исполняемые файлы http://jorik.sourceforge.net], а заодно убедить вас, что работа с GPU не так уж и сложна, как может показаться.
 |
Тест 1. Решается динамическая задача распространения звуковых волн в двухмерном пространстве (см. рис.) при помощи простейшей разностной схемы на сетке 1536x1536. Как уже было сказано, такого рода задачи идеально подходят для GPU. Результат неудивителен — GPU может справиться с заданием в десять с лишним раз быстрее (табл. 1).
 |
Примечательно другое. Во-первых, расстановка плат по производительности в играх и в неграфических приложениях может сильно отличаться. Во-вторых, на бюджетной плате ATI Radeon 9600 установлена такая же обычная память, что и на многих системных платах: 200 МГц DDR SDRAM 128 бит (аналог двухканального режима). Оказывается, огромное ускорение может быть получено даже без быстрой и дорогой графической памяти топовых моделей!
Тест 2. Любопытно также рассмотреть другую крайность — «неудобную» для GPU задачу. Производится сортировка массива из 16 млн. действительных чисел. Здесь CPU выполняет алгоритм быстрой сортировки (STL quick sort), GPU — параллельной битонической сортировки (см. выше). В результате разного количества операций в алгоритмах быстрая видеокарта лишь приближается к центральному процессору (табл. 2).
 |
Тест 3. Исследуется скорость копирования многомегабайтной текстуры, где каждый пиксел содержит четыре 32-битных действительных числа, из системной памяти в видеопамять и обратно. Эта скорость важна, потому что она определяет, какие задачи имеет смысл доверять GPU. Если задача проста, то преимущество GPU может быть нивелировано временем передачи данных к нему. Поэтому выгода получается только на крупных задачах, обсчет которых занимает гораздо больше времени, нежели пересылка данных. Результаты[Их достоверность перепроверялась пакетом GPUBench, скорость для платы nVidia близка к данным презентации "Interactive Geometric Computations using Graphics Processors"] теста оказались просто обескураживающими (табл. 3).
 |
Эти скорости не только ниже 4 Гбит/с шины PCI-Express, но, пожалуй, и самых первых версий AGP. Хочется надеяться, результаты столь низки оттого, что современным играм не приходится часто выполнять копирование больших текстур, особенно описанного формата, и мы имеем дело всего лишь с временной недоработкой драйверов.
До проведения тестирования предполагалось, что использующие GPU программы практически не будут загружать центральный процессор. Действительность оказалась не такой радужной. Нагрузка была очень высокой, доходя до 100%, так что даже окошки по экрану перетаскивались с трудом. Эффект наблюдался и для DirectX-, и для OpenGL-приложений. И еще нельзя не отметить, что плата ATI при большей сетке в первом тесте и при некоторых других обстоятельствах приводила к синему экрану смерти — это уж совсем никуда не годится.
| © 2024 Библиотека RealLib.org (support [a t] reallib.org) |