"Язык как инстинкт" - читать интересную книгу автора (Пинкер Стивен)
Глава 6 ЗВУКИ ТИШИНЫ[72] Речь и звуки, из которых она складывается
В студенческие годы я работал в лаборатории университета Мак-Джилл, где изучалось восприятие речи на слух. Используя компьютер, я синтезировал цепочки накладывающихся друг на друга тонов и определял, звучат ли они как один смешанный звук или как два чистых. Как-то утром в понедельник случилось странное: тоны вдруг превратились в хор вопящих жевунов[73]. Вот так:
(биип-бууп-бууп) (биип-бууп-бууп) (биип бууп-бууп) ХАМПТИ-ДАМПТИ[74]-ХАМПТИ-ДАМПТИ-ХАМПТИ-ДАМПТИ-(биип-бууп-бууп) (биип бууп-бууп) ХАМПТИ-ДАМПТИ-ХАМПТИ-ДАМПТИ-ХАМПТИ-ДАМПТИ-ХАМПТИ-ДАМПТИ-(биип бууп-бууп) (биип бууп-бууп) (биип бууп-бууп) ХАМПТИ-ДАМПТИ-(биип бууп-бууп) ХАМПТИ-ДАМПТИ (биип бууп-бууп).
Я проверил осциллоскоп — два потока тонов, как и запрограммировано. Должно быть, это эффект восприятия. Сделав небольшое усилие, я мог услышать этот звук или как
Годы спустя я, наконец, открыл, в чем состояло мое открытие. Психологи Роберт Ремез, Дэвид Пизони и их коллеги, более смелые, чем я, опубликовали в журнале «Сайенс» статью о «речи синусоидной волны» («sine-wave speech»). Они синтезировали три тона с синхронными колебаниями. С физической точки зрения, звук ничем не напоминал речь, но тоны соответствовали тем же очертаниям, что и дорожки магнито-записи предложения
Наш мозг колеблется между восприятием чего-либо как сигнал компьютера или как слово, потому что фонетическое восприятие напоминает шестое чувство. Когда мы слышим речь, то звуки фактически проникают в одно ухо и выходят из другого; то, что мы в результате этого воспринимаем и есть
На самом деле не нужно никакого электронного колдовства, чтобы создать иллюзию речи. Вся речь — это иллюзия. Мы слышим речь как поток отдельных слов, но в отличие от падения дерева в лесу, где никто не может его услышать, неслышимая граница слова просто беззвучна. В волне звуков речи одно слово набегает на другое без зазоров, и между произносимыми словами нет никаких маленьких промежутков, в отличие от слов на письме. Мы просто воображаем границу слова, когда достигаем конца звукового участка, который соответствует какой-то статье в нашем ментальном словаре. Это становится очевидно, когда мы слушаем речь на иностранном языке: невозможно сказать, где заканчивается одно слово и начинается другое. «Бесшовная» структура речи в явном виде предстает в «оронимах» — линейных последовательностях звуков, которые можно разбить на слова двумя разными способами:
Оронимы часто используются в песнях и детских стишках:
Некоторые оронимы были случайно обнаружены преподавателями, читавшими курсовые работы и домашние задания студентов:
Jose
Даже последовательность звуков, которые, как нам кажется, мы слышим в слове, является иллюзией. Если разрезать магнитофонную пленку с записью произнесенного слова
Восприятие речи — это еще одно биологическое чудодейство, составляющее языковой инстинкт. В использовании рта и ушей как каналов коммуникации есть очевидные преимущества, и мы не найдем ни одно сообщество обладающих слухом людей, которое предпочло бы жестовый язык, хотя он точно так же выразителен. Речь не требует хорошего освещения, видения лица собеседника или полного задействования рук и глаз; слова можно прокричать издалека или прошептать, чтобы сказанное осталось втайне. Но, чтобы воспользоваться преимуществами звуковой передачи информации, речь должна преодолеть ту проблему, что ухо — это узкий информационный канал. Когда в 40-х годах инженеры впервые пытались изобрести читающие машины для слепых, они создали набор шумов, которые соответствовали буквам алфавита. Даже после усиленной тренировки люди не могли различать эти звуки быстрее, чем хорошие операторы азбуки Морзе, — три единицы в секунду. Живая речь почему-то воспринимается на порядок быстрее: от десяти до пятнадцати фонем в секунду при восприятии обычной речи, от двадцати до тридцати в секунду при прослушивании рекламы, идущей в вечерние часы, и до сорока — пятидесяти в секунду при искусственно ускоренной речи. Учитывая то, как работает человеческая система восприятия речи на слух, в это трудно поверить. Когда какой-либо звук, например, щелчок, повторяется со скоростью двадцать раз в секунду или быстрее, мы слышим его уже не как последовательность отдельных звуков, но как тихий шум. Если мы слышим сорок пять фонем в секунду, то фонемы вряд ли могут быть последовательностью отдельных звуков; должно быть, несколько фонем «упаковано» в каждом моменте звучания речи, а наш мозг каким-то образом «распаковывает» их. В результате речь — это самый быстрый способ получить информацию с помощью слуха.
Ни одна изобретенная человеком система не может сравниться с самим человеком в расшифровке речи. И не потому, что в такой системе нет необходимости, или, что в ее разработку не вкладывалось много усилий. Распознаватель речи был бы незаменим для слепых и других инвалидов, для профессионалов, которым нужно внести информацию в компьютер, в то время, когда заняты их руки или глаза, для тех, кто не научился печатать на машинке, для тех, кто пользуется телефонными услугами и для растущего числа машинисток, которые становятся жертвами синдрома повторяющихся движений. Поэтому не удивительно, что инженеры уже более сорока лет бьются над тем, чтобы заставить компьютер распознавать звучащее слово. Но им пришлось встать перед выбором: или, или. Если от системы требуется выслушивать большое количество людей, она может распознавать только очень небольшое количество слов. Например, телефонные компании начинают устанавливать вспомогательные справочные системы, которые могут распознать слово «да», сказанное любым человеком, или (для более продвинутых систем) названия десяти цифр, произносимых на английском языке, которые, к счастью для инженеров, звучат совершенно по-разному. Но если от системы требуется распознавать большое количество слов, то она должна быть приспособлена к голосу одного и того же говорящего. Ни одна система на сегодняшний день не может продублировать человеческую способность распознавать много слов и многих говорящих. Возможно, наивысшим достижением является система DragonDictate, написанная для персонального компьютера и способная распознавать 30 000 слов. Но у нее есть несколько ограничений. Ее нужно долго приспосабливать к голосу пользователя. С… ней… нужно… разговаривать… так — с паузами в четверть секунды между словами (таким образом, она действует на одной пятой скорости обычной речи). Если нужно использовать слово, которого нет в словаре, например, имя, то придется проговорить его по буквам, пользуясь специальной азбукой «Alpha, Bravo, Charlie»[75]. И тем не менее, приблизительно в пятнадцати процентах случаев программа путает слова — наблюдается более, чем одно перепутанное слово на предложение. Этот замечательный программный продукт не может сравниться даже с посредственной стенографисткой.
Физический и нейронный механизм речи являются решением двух проблем в строении системы человеческой коммуникации. Человек может знать 60 000 слов, но его речевой аппарат не может издать 60 000 различных шумов, по крайней мере тех, которые можно легко различить на слух. Отсюда следует, что язык снова использует принцип дискретной комбинаторной системы. Предложения и синтаксические группы строятся из слов, слова строятся из морфем, а морфемы, в свою очередь — из фонем. Хотя, в отличие от слов и морфем, фонемы не несут порции информации, из которых складывается целое. Значение слова
Но у фонологического модуля языкового инстинкта имеются и иные задачи помимо проговаривания морфем по буквам. Языковые правила — это дискретные комбинаторные системы: фонемы четко заскакивают в морфемы, морфемы — в слова, слова — в синтаксические группы. Они не смешиваются, не сливаются и не путают высказывание:
Таким образом, звуки языка сгруппировываются вместе в несколько этапов. Единицы, отобранные из ограниченного набора фонем ставятся в порядке, необходимом для идентификации слов, а получившиеся в итоге цепочки фонем видоизменяются так, чтобы облегчить произношение и понимание, прежде, чем начинается их артикуляция. Я проведу вас по каждому из этих этапов и покажу, как благодаря им возникают следующие связанные с речью явления: стихи и песни, послышавшиеся звуки, акценты, понимающие речь механизмы и сумасшедшее английское правописание.
Один из простых путей понять, что же такое звуки речи — это проследить движение объема воздуха по речевому аппарату наружу из легких.
Когда мы говорим, мы изменяем своему обычному ритмичному дыханию и делаем быстрые вдохи, а затем равномерно выпускаем воздух, используя реберные мышцы, чтобы противодействовать силе эластической тяги легких. (Если бы мы этого не делали, наша речь звучала бы как жалобное завывание спускаемого надувного шарика.) Синтаксис берет верх над углекислым газом: мы подавляем функции тонко настроенного узла обратной связи, контролирующего частоту дыхания для регулярности забора кислорода, и вместо этого растягиваем время выдоха до длины высказывания, которое желаем сделать. Это может привести к легкой гипервентиляции или гипоксии; вот почему так изнурительна речь на публике и почему так трудно поддерживать разговор с партнером, бегущим трусцой.
Воздух покидает легкие через трахею (воздушную трубку), которая ведет в гортань (центр голосообразования, который виден снаружи — это кадык, или адамово яблоко). Гортань — это клапан, состоящий из отверстия — голосовой щели — закрытой двумя лоскутами сократимой мышечной ткани, называемой голосовыми складками (они также называются «голосовыми связками» из-за ошибки в ранних анатомических исследованиях; они вовсе не являются связками)[76]. Голосовые связки могут плотно смыкать голосовую щель, «запечатывая» легкие. Это необходимо, когда мы хотим увеличить жесткость верхней части тела, являющейся мягким воздушным резервуаром. Поднимитесь со стула без помощи рук — вы почувствуете, как напрягается гортань. Гортань также перекрывается при осуществлении физиологических функций, таких как кашель или дефекация. Хрип штангиста или игрока в теннис — это напоминание о том, что мы используем один и тот же орган, чтобы запечатывать легкие и продуцировать звуки.
Голосовые связки могут также частично прикрывать голосовую щель, чтобы производить шум при прохождении через них воздуха. Так происходит потому, что проходящий под большим давлением воздух раздвигает голосовые связки до полного открытия, после чего они устремляются назад и смыкаются, перекрывая голосовую щель, пока их снова не раздвинет давление воздуха, начиная новый цикл. Дыхание, таким образом, разбивается на циклы изгнания воздуха, которые мы воспринимаем как шум под названием «звонкость». Этот шум можно услышать и почувствовать, если произнести звук
Частота открытия и закрытия голосовых связок обуславливает высоту голоса. Меняя степень напряжения и положение голосовых связок, можно контролировать эту частоту и, таким образом, высоту. Это можно ясно наблюдать во время пения или «мурлыкания» мелодии, но мы также можем постоянно изменять высоту голоса на протяжении предложения — этот процесс называется интонацией. Нормальная интонация — это то, благодаря чему естественная речь звучит отлично от речи роботов в старых научно-фантастических фильмах и от речи «конусоголовых» в «Сэтердей найт лайв». Интонации также уделяется особое внимание в сарказмах, при логическом ударении и тогда, когда тон голоса становится эмоциональным — во время гнева или ликования. В «тональных» языках, таких как китайский, поднимающиеся или падающие тоны являются смыслоразличительным признаком для гласных.
Хотя звонкость и создает звуковую волну с доминирующей частотой вибрации, это не то же самое, что камертон или позывные радиостанции «Имердженси Бродкастинг Систем» — чистый тон с единственной частотой. Звонкость — это интенсивный шум со множеством обертонов. Мужской голос — это волна с вибрациями не только при 100 Гц, но и при 200, 300, 400, 500, 600, 700 Гц и так далее вплоть до 4000 Гц и больше. Женский голос вибрирует при 200, 400, 600 Гц и так далее. Интенсивность источника звука имеет решающее значение — это то сырье, из которого остальная часть голосового тракта формирует гласные и согласные.
Если по каким-то причинам мы не можем издавать шум гортанью, подойдет любой интенсивный источник звука. Когда мы шепчем, мы раздвигаем голосовые связки, заставляя поток воздуха хаотически разбиваться об их выступы и создавая турбулентность или шум, который звучит как шипение или радио-помехи. Шипящий шум — это не с определенной периодичностью повторяющаяся волна, состоящая из последовательности обертонов, которую мы встречаем в обладающем периодичностью звуке человеческого голоса, но неровная зазубренная волна, состоящая из мешанины постоянно изменяющихся частот. Тем не менее этой мешанины достаточно остальному голосовому тракту для продуцирования внятного шепота. Некоторые пациенты, перенесшие ларинготомию, учатся чревовещанию, или управляемому рычанию, которое обеспечивает необходимый шум. Другие помещают на шею вибратор. В 1970 г. гитарист Питер Фрэмптон пропустил усиленный звук своей электрогитары через трубку себе в рот, что позволило ему во время выступления выправлять свою гнусавость. Благодаря этому эффекту он записал пару хитов, прежде чем погрузиться в рок-н-ролльное забвение.
Затем, прежде чем покинуть голову, интенсивно вибрирующий воздух проходит через анфиладу полостей: горло, или «фаринкс», находящееся позади языка, область рта между языком и нёбом, отверстие между губами и альтернативный путь во внешний мир через нос. Каждая полость имеет определенную длину и форму, которые влияют на проходящий звук посредством явления под названием «резонанс». У звуков разных частот разная длина волны (расстояние между соседними гребнями звуковой волны); у высоких звуков длина волны короче. Звуковая волна, идущая по трубе, отражается назад, достигнув отверстия на другом конце. Если длина трубы кратна длине звуковой волны, то каждая отраженная волна усиливает идущую за ней; если же она не кратна длине волны, то они гасят друг друга. (Это сходно с тем, как можно достичь наилучшего эффекта, раскачивая ребенка на качелях — нужно синхронизировать каждый толчок с самым высоким положением качелей.) Отсюда следует, что труба определенной длины «отфильтровывает» звуковые частоты, усиливая одни и гася другие. Этот эффект можно наблюдать во время наполнения жидкостью бутылки. Шум падающей воды изменяется воздушной прослойкой между входным отверстием и донышком: чем больше воды, тем меньше прослойка, тем выше резонансная частота этой прослойки, и тем более высокий, металлический звук у булькания.
То что мы слышим как различные гласные звуки — это различные комбинации усиления и гашения звука, идущего из гортани. Эти комбинации порождаются изменением положения пяти органов речи в ротовой полости, благодаря чему резонансные полости, по которым проходит звук, изменяют форму и длину. Например, звук, обозначаемый буквами
Язык
Связь между положением языка и разными гласными звуками, которые он образовывает, порождает одну своеобразную особенность английского и многих других языков, носящую название фонетического символизма. Когда язык находится в переднем положении в верхней части рта, он создает там маленькую резонансную полость, которая усиливает некоторые высокие частоты, и получающиеся в результате звуки, например, выражаемые буквами
И, рискуя уподобиться Энди Руни из передачи «Сиксти минитс»[77], я хочу спросить: вы никогда не задавались вопросом, почему мы говорим
Давайте рассмотрим другие органы речи. Обратите внимание на свои губы, произнося по очереди гласные в словах
Помните, как ваша школьная учительница рассказывала вам, что гласные звуки в словах
Вы можете ощутить, как действует пятый орган речи, протянув гласные звуки в словах
До сих пор мы обсуждали гласные — звуки, при образовании которых воздух напрямую проходит из гортани наружу. Когда на этом пути появляется какое-либо препятствие, то получается согласный звук. Произнесите
Теперь произнесите
И наконец, произнесите
Почему мы говорим
Теперь, когда завершено путешествие по голосовому тракту, вы имеете представление о том, как образуется и становится слышимым огромное большинство звуков в языках мира. Хитрость заключается в том, что звук речи — это не одно-единственное движение одного органа. Каждый звук речи — это
{пустая ячейка таблицы} — Назальный (Нёбная занавеска поднята) — Не назальный (Нёбная занавеска опущена)
Губы —
Кончик языка —
Корпус языка —
Аналогично, звонкость комбинируется всеми возможными способами с тем или иным органом речи:
{пустая ячейка таблицы} — Звонкий (Гортань издает шум) — Глухой (Гортань не издает шума)
Губы —
Кончик языка —
Корпус языка —
Таким образом звуки речи аккуратно заполняют столбцы, ряды и ярусы многомерной матрицы. Во-первых, один из шести органов речи выбирается в качестве основного для артикуляции: гортань, нёбная занавеска, корпус языка, кончик языка, корень языка или губы. Во-вторых, выбирается способ, которым этот орган осуществляет артикуляцию: щель, смычка или гласность. В-третьих, может быть точно установлена конфигурация остальных органов речи: для нёбной занавески — назальность или ее отсутствие, для гортани — глухость или звонкость, для корня языка — напряженность или ненапряженность, для губ — округленность или неокругленность. Каждый вариант конфигурации является символом для набора команд для мышц органов речевого аппарата и такие символы называются признаками. Для артикуляции фонемы эти команды должны быть выполнены в совершенно определенный временной промежуток, это самые сложные гимнастические упражнения, которые нам приходится исполнять.
Для английского языка перебор этих комбинаций определяет 40 фонем, несколько больше среднего уровня для языков мира. В других языках это количество варьируется от 11 (полинезийский) до 141 (хойсан, или язык бушменов). А весь целиком список фонем для языков мира насчитывает тысячи, но все они определяются комбинациями шести органов речи, их положения и формы. Другие звуки, издаваемые ртом, не используются ни в одном языке, например: скрежетание зубами, цокание языком, фыркание и пронзительный крик, подобный крику Дональда Дака. Даже непривычные щелчки в языках хойсан и банту (сходные со звуком
Фонемный состав — это одна из тех вещей, которые придают языку его характерное звучание. Например, японский язык знаменит тем, что он не различает
Мы часто узнаем характерное звучание языка даже в том потоке речи, который не содержит реально существующие слова, как, например, у шведского повара в шоу «Маппетс» или в «самурайской» речи Джона Белуши. Лингвист Сара Г. Томасон обнаружила, что люди, заявляющие, будто помнят свои прошлые жизни или неожиданно начинающие говорить на незнакомых до этого языках, действительно выдают некую тарабарщину, смутно напоминающую заявленный язык по характерному звучанию. Например, находясь под гипнозом, одна такая женщина, заявлявшая, что она болгарка, жившая в девятнадцатом веке и разговаривавшая со своей матерью о солдатах, опустошавших их местность, выдавала нечто псевдославянское:
Ovishta reshta rovishta. Vishna beretishti? Ushna barishta dashto. Na darishnoshto. Korapshnoshashit darishotoy. Aobashni bedetpa.
И, конечно, когда слова на одном языке произносятся со звучанием, характерным для другого языка, мы называем это иностранным акцентом, как в нижеприведенном отрывке из незаконченной сказки Боба Белвисо:
GIACCHE ENNE BINNESTAUCCHE
Uans appona taim uase disse boi. Neimmese Giacche. Naise boi. Live uite ise mamma. Mainde da cao.
Uane dei, di spaghetti ise olle ronne aute. Dei goine feinte fromme no fudde. Mamma soi orais, «Oreie Giacche, teicche da cao enne traide erra forre bocchese spaghetti enne somme uaine».
Bai enne bai commese omme Giacche. I garra no fudde, i garra no uaine. Meichese misteicche, enne traidese da cao forre bonce binnese.
Giacchassc!
Что определяет характерное звучание языка? Это должно быть нечто большее, чем просто множество фонем. Рассмотрим следующие слова:
Все составляющие их фонемы есть в английском языке, но любой, для кого этот язык является родным, определит, что слова
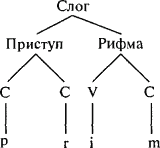 |
Правила, по которым создаются слоги, определяют виды слов, имеющие и не имеющие право существовать в языке. В английском приступ может состоять из группы согласных, например:
Приступы и рифмы не просто определяют, может ли звук существовать в языке, они являются теми частями звучащего слова, которые наиболее бросаются в глаза, и потому именно ими оперируют в стихосложении и игре слов. У рифмующихся слов общая рифма, у слов с аллитерацией общий приступ (или просто начальный гласный). Pig Latin, eggy-peggy, aygo-paygo и другие тайные детские языки имеют тенденцию сращивать слова на границе приступа и рифмы, и то же самое происходит в таких конструкциях на Yinglish[80], как:
В свою очередь, слоги собираются в ритмические группы под названием
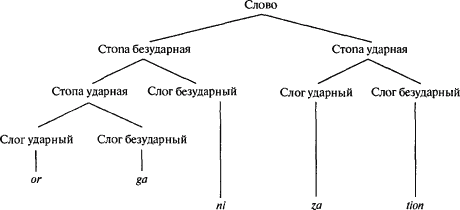 |
Слоги и стопы классифицируются как ударные и безударные в соответствии с другими правилами, и схема расположения ударных и безударных ветвей определяет, насколько напряженным будет этот слог при его произнесении. Стопы, так же как и приступы и рифмы, это наиболее заметные составляющие сло́ва, которыми мы склонны манипулировать в стихосложении и при игре слов. Стихотворный размер определяется теми видами стоп, которые выстраиваются в строку. Последовательность стоп, при которой сначала идет ударный слог, а потом — безударный, называется хореем, например:
Фонемный состав в морфемах и словах, хранящихся в памяти, претерпевают ряд аккомодаций прежде чем в итоге получить звуковое выражение, и эти аккомодации продолжают формирование звуковой модели языка. Произнесите слова
Интересно то, что фонологические правила действуют последовательно, как если бы слова собирались из фонем на конвейере. Произнесите
Теперь произнесите
Обратите внимание на другую важную черту правила, изменяющего гласные звуки. Звук
Значит ли это, что существуют пять различных правил, которые изменяют
Такая избирательность действует не только в английском, но и во всех языках. Фонологические правила редко приводятся в действие какой-то одной фонемой, они приводятся в действие целым классом фонем, обладающих одним или двумя общими признаками (такими как: звонкость, смычность в противоположность фрикативности или артикуляции с помощью того или иного органа). Это предполагает, что правило «смотрит» не на фонемы, выстроенные в цепочку, а сквозь них на те признаки, которые их образуют.
И правила манипулируют именно признаками, а не самими фонемами. Произнесите следующие формы прошедшего времени:
В словах
У читателей, имеющих вкус к утонченному теоретизированию, может возникнуть желание проследовать за мной еще по одному параграфу. Обратите внимание на необыкновенные свойства той схемы, по которой работает правило изменения
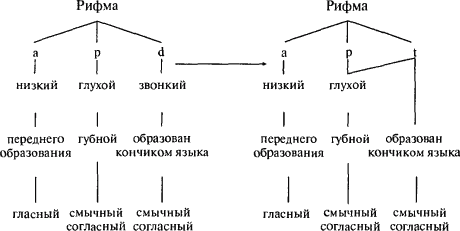 |
Глухость
Итак, фонологические правила «видят» признаки, а не фонемы, и производят аккомодацию признаков, а не фонем. Вспомните также, что языки склонны создавать свой фонемный состав, перебирая различные комбинации некоего набора признаков. Эти факты показывают, что именно признаки, а не фонемы являются атомами звуков языка, которые хранятся и с которыми производятся манипуляции в мозге. Фонема — это просто пучок признаков. Таким образом, даже имея дело со своими наименьшими единицами — признаками — язык работает с использованием комбинаторной системы.
Фонологические правила есть в каждом языке, но для чего они нужны? Как вы могли заметить, они часто облегчают произношение. «Схлопывание»
У англичан нет уважения к своему языку, и они не учат своих детей говорить на нем. Они не могут правильно писать на нем, потому что у них нет для этого никаких средств, кроме старого иностранного алфавита, в котором только у согласных, и то не у всех, есть какое-то общепризнанное речевое значение. Следовательно, англичанин не может открыть рот, чтобы его немедленно не начал презирать какой-то другой англичанин.
В своей статье «Howta Reckanize American Slurvian» (искаженное: «Как опознать американца с кашей во рту») Ричард Ледерер пишет:
Любители языка долго сокрушались по поводу печального состояния произношения и артикуляции в Соединенных Штатах. С гневом и яростью люди, наделенные, на свою беду, чутким слухом, содрогаются, слыша такое невнятное бормотание, как
Но если бы слух этих несчастных был еще немного чувствительнее, они могли бы заметить, что на самом деле не существует диалекта, в котором бы преобладала речевая неаккуратность. Фонологические правила дают одной рукой и отбирают другой. Те же «деревенщины», которых высмеивают за опускание звука
Существует веская причина того, почему так называемая леность в произношении на самом деле строго ограничена фонологическими правилами и почему, исходя из этого, ни один диалект не позволяет говорящим на нем произвольно срезать углы. Каждый акт речевой небрежности со стороны говорящего требует компенсации в виде умственного усилия со стороны партнера по разговору. Общество ленивых говорунов станет обществом усердно трудящихся слушателей. Если бы говорящие действовали, как им заблагорассудится, то все фонологические правила сводились бы к аккомодации, редуцированию и опусканию. Но если бы слушатели действовали, как им заблагорассудится, фонологии пришлось бы производить противоположную операцию: подчеркивать акустические различия между фонемами, которые возможно спутать, заставляя говорящих преувеличенно отчетливо их произносить. И действительно, многие фонологические правила так и делают. (Например, существует правило, которое вынуждает носителей английского языка округлять губы, произнося
Фонологические правила помогают слушающим и тогда, когда им не нужно подчеркивать какую-либо акустическую разницу. Поскольку эти правила делают модели речи предсказуемыми, они сообщают языку избыточность. Подсчитано, что английский текст в два-четыре раза длиннее, чем он должен был бы быть, исходя из содержащейся в нем информации. Например, на моем компьютерном диске эта книга занимает около 900 000 знаков, но программа сжатия файла может воспользоваться избыточностью в последовательностях букв и сжать эту книгу до 400 000 знаков; те компьютерные файлы, которые не содержат английского текста, не могут даже отчасти рассчитывать на такое сжатие. Ученый-логик Квай так объясняет причины, по которым во многих системах заложена избыточность:
Это диктуемый здравомыслием избыток при имеющемся необходимом минимуме. Именно поэтому хороший мост не рассыпается на куски, когда ему приходится выдерживать нагрузку больше предусмотренной. Это страховка от провалов. Именно поэтому мы используем столько слов, чтобы отправить почту в тот или иной город и страну, несмотря на почтовый код. Одна неразборчиво написанная цифра в коде может все испортить… Легенда рассказывает как королевство погибло потому, что в кузнице не было гвоздя, чтобы подковать коня. Избыточность — эта страж, предохраняющий от такой чрезвычайной ситуации.
Благодаря избыточности в языке вх мхжхтх пхнхть, чтх х пхшх, дхжх хслх х зхмхнх всх глхснхх нх «х» (сл в н знт, гд стт глсн, т бдт нмнг трдн)[90]. При понимании речи избыточность, обеспечиваемая фонологическими правилами, может компенсировать двусмысленность, вызванную звуковой волной. Например, слушающий может быть уверен, что
Так почему же нация, которая может запустить человека на Луну, не может сконструировать компьютер, который будет воспринимать диктовку? В соответствии с тем, что я до сих пор объяснял, каждая фонема должна иметь свидетельствующее о ней акустическое выражение: набор резонансов для гласных, вызывающая шум преграда для фрикативных, и последовательность «тишина — взрыв — переход» для смычных. Последовательности фонем обрабатываются предсказуемым образом идущими по порядку фонологическими правилами, результаты действия которых были бы, очевидно, сведены на нет, если бы правила применялись в обратном порядке.
Причина, по которой понимание речи вызывает такие трудности, в том, что на пути между мозгом и губами много раз можно поскользнуться. Нет двух совершенно одинаковых человеческих голосов, различаться будут и формы голосового тракта, формирующего звуки, и индивидуальная манера артикуляции. Фонемы также звучат очень по-разному, в зависимости от того, насколько они напряженные и как быстро их произносят; в быстрой речи многие просто проглатываются.
Но главная причина того, почему электронная стенографистка не ждет вашего вызова за дверью, связана с общим явлением, возникающим при управлении мускулатурой, и называемым коартикуляцией. Поставьте перед собой блюдце и на расстоянии около полуметра от нее — кофейную чашку. Теперь быстро дотроньтесь до блюдца и схватите чашку. Вы наверняка дотронулись до края блюдца, ближнего к чашке, а не ровно посредине. Ваши пальцы наверняка пришли в позицию, удобную для хватания, в то время, как рука двигалась по направлению к чашке, но прежде, чем достигла цели. Такой плавный переход от одного жеста к другому и накладывание жестов повсеместно встречаются при осуществлении моторных функций. Это экономит силы, необходимые для движения частей тела и уменьшает нагрузку на суставы. Язык и гортань не являются исключением. Когда мы намереваемся артикулировать фонему, наш язык не может немедленно занять требуемую позицию: это увесистый кусок мяса, которому нужно время, чтобы переместиться. Поэтому пока мы его перемещаем, наш мозг планирует траекторию, уже представляя себе следующее положение, совсем как в случае с блюдцем и чашкой. Изо всех возможных позиций в полости рта, которые могут определить фонему, мы помещаем язык в ту, при которой наибыстрейшим образом может быть артикулирована следующая фонема. Если фонемой, которую мы сейчас произносим, не задано, где в точности должен находиться орган речи, мы предугадываем, где он должен находиться для произнесения следующей фонемы, и помещаем его туда заранее. Большинство из нас находится в полном неведении об этих аккомодациях, пока к ним не привлекут внимания. Произнесите
Поскольку звуковые волны мгновенно реагируют на форму полостей, по которым они проходят, то коартикуляция сеет смуту среди звуков речи. Индивидуальная звуковая реализация той или иной фонемы «подкрашена» теми фонемами, которые идут перед ней и после нее, иногда до такой степени, что эта звуковая реализация не имеет ничего общего с фонемой благодаря компании других фонем. Вот почему невозможно отрезать кусок пленки с записью звучащего слова
Конечно, человеческий мозг — это высоко технологичный распознаватель речи, однако, никто не знает, как ему удается быть таковым. Поэтому психологи, изучающие восприятие речи, и инженеры, конструирующие механизмы для распознавания речи, пристально наблюдают за работой друг друга. Возможно, распознавание речи — настолько сложный процесс, что существует всего несколько способов того, как оно в принципе может быть реализовано. Если так, то способ, которым пользуется мозг, может подсказать, как наилучшим образом сконструировать машину для распознавания речи, а способ, каким это удастся сделать машине, может предложить гипотезу о том, как это удается мозгу.
Уже на ранних этапах истории исследований речи стало ясно, что слушающие способны с выгодой для себя использовать свои представления о речевых намерениях говорящего. Последние сужают круг вариантов, возможных при акустическом анализе речевых сигналов. Мы уже заметили, что фонологические правила обеспечивают один вид избыточности, который можно использовать, но люди в состоянии пойти еще дальше. Психолог Джордж Миллер проиграл записи предложений, произносимых на фоне шума, и попросил людей в точности повторить, что они слышали. Некоторые предложения соответствовали правилам английского синтаксиса и имели смысл:
Другие предложения были получены «перемешиванием» слов из разных синтаксических групп, что дало бесцветно-зелено-мысленные предложения, грамматически правильные, но бессмысленные:
Третий вид предложений был получен «перемешиванием» непосредственно составляющих в структуре при сохранении в предложении одних и тех же слов:
И наконец, некоторые предложения были просто словесным винегретом, как например:
Люди лучше всего справились с имеющими смысл грамматически правильными предложениями, хуже — с грамматически правильной бессмыслицей и грамматически неправильным смыслом, а хуже всего — с грамматически неправильной бессмыслицей. Несколько лет спустя психолог Ричард Уоррен записал на пленку предложения типа:
Вы можете подумать, что звуковая волна находится на нижнем уровне иерархии «звуки — фонемы — слова — синтаксические группы — значения предложений — знание вообще». Но то, что было продемонстрировано выше, явно подразумевает, что восприятие человеком речи осуществляется сверху вниз скорее, чем снизу вверх. Возможно, мы постоянно пытаемся догадаться, что собирается сказать говорящий, используя каждую находящуюся в нашем распоряжении крупицу осознанного и неосознанного знания, начиная со знания о том, как коартикуляция «смазывает» звуки, до знания правил английской фонологии, английского синтаксиса, знаний о производителях и объектах действия, и о том, что в данный момент на уме у собеседника. Если наши предположения достаточно точны, то акустический анализ может быть очень поверхностным: то, чего не достает звуковой волне, заполнит контекст. Например, если вы слушаете дискуссию о разрушении экологических сред обитания, вы можете заранее настроиться на слова, относящиеся к исчезающим животным и растениям, и тогда, когда вы слышите звуки, в которых невозможно разобрать фонемы, например:
Теория восприятия речи «сверху вниз» производит на некоторых людей сильное эмоциональное впечатление. Она подтверждает философию релятивистов о том, что мы слышим то, что надеемся услышать, что наше знание определяет наше восприятие и, наконец, что мы не находимся в прямом контакте с объективной реальностью. В каком-то смысле восприятие, упрямо идущее сверху вниз, может стать едва управляемой галлюцинацией, в этом-то и проблема. Человек, воспринимающий речь и вынужденный полагаться на свои ожидания, находится в очень невыигрышном положении в том мире, который непредсказуем даже при самых благоприятных обстоятельствах. Есть основания полагать, что восприятие человеческой речи в сильной степени определяется на акустическом уровне. Если у вас есть готовый к сотрудничеству друг, вы можете проделать следующий эксперимент: выберите наугад из словаря десять слов, позвоните другу и четко произнесите эти слова. Весьма вероятно, что друг легко сможет их воспроизвести, полагаясь только на данные звуковой волны и на свое знание английского словаря и фонологии. Ваш друг не мог использовать никаких относящихся к высокому уровню предположений относительно структуры высказывания, контекста, или связанной с ним истории, поскольку у множества слов, выбранного наугад, их нет. Хотя при плохой слышимости или на фоне помех мы и можем сослаться на теоретическое знание, относящееся к высокому уровню (но даже и здесь не совсем ясно, действительно ли знание воздействует на восприятие, или оно позволяет нам сделать адекватную догадку постфактум), наш мозг кажется устроенным так, чтобы до последней капли выжимать фонетическую информацию из самой звуковой волны. Наше шестое чувство может воспринимать речь как язык, а не как просто звук, но это —
Другой пример того, что восприятие речи не есть точное воплощение наших ожиданий, дает нам иллюзия, которую журналист Джон Кэрролл назвал «мондегрин» после того, как неправильно воспринял строку из народной баллады «The Bonny Earl O’Moray»:
Кэрролл всегда думал, что строки звучали так:
‘Вот идет девушка, больная колитом. [Девушка с калейдоскопическими глазами.]’
‘Отче наш и иже с ним на небеси, Харольд будет их имя… Не приведи нас на станцию Пенн. [Отче наш, иже еси на небеси, да святится имя твое… Не введи нас во искушение.]’
‘Он выжимает сок из винограда там, где гроздья упаковываются и хранятся. [… хранятся гроздья гнева.]’
‘Радостно косоглазый медведь. [С радостью я понесу крест.]’
‘Я никогда не буду твоей подгоревшей пиццей. [… твоей тяжелой ношей]’
‘Это радостная дюна, и ты думаешь, что утонешь в ней. [Здесь полдюйма воды…]’
«Мондегрины» интересны тем, что послышавшиеся слова, как правило,
Об этом же свидетельствует и история искусственных распознавателей речи. В 1970-х гг. группа исследователей искусственного интеллекта при университете Карнеги-Меллон, возглавляемая Раджем Редди, создала компьютерную программу под названием HEARSAY, которая использовала голосовые команды, чтобы перемещать шахматные фигуры. Находясь под влиянием теории восприятия речи «сверху — вниз», они создали эту программу как «содружество» «экспертных» субпрограмм, действующих сообща с целью дать наиболее вероятную интерпретацию сигнала. Там были субпрограммы, специализирующиеся на акустическом анализе, на фонологии, на синтаксисе, на лексике, на правилах перемещения шахматных фигур, даже на шахматной стратегии применительно к развитию игры. Рассказывают, что на демонстрацию программы явился генерал из министерства обороны, спонсировавшего исследования. Пока ученые обливались холодным потом, генерала усадили напротив шахматной доски и микрофона, соединенного с компьютером. Генерал откашлялся. Программа напечатала: «Пешка — король 4».
Недавно созданная программа DragonDictate, упомянутая ранее в этой главе, делает больший упор на акустический, фонологический и лексический анализ, и, похоже, что этим объясняется ее больший успех. В программе имеется словарь, где слова представлены так же как последовательности фонем. Чтобы помочь предвидеть результаты действия фонологических правил и коартикуляции, в программе задано, как звучит каждая английская фонема в окружении любых возможных предшествующих и последующих фонем. Для каждого слова эти сопутствующие фонемы объединены в цепочку и при каждом переходе от одной звучащей единицы к другой заложена вероятностная характеристика. Цепочка выполняет функции среднестатистической модели говорящего человека, и когда эту систему использует реальный говорящий, вероятностные характеристики в цепочке варьируются таким образом, чтобы приспособиться к манере речи данного человека. Самому слову также присваивается процент вероятности, зависящий от его частотности в языке и от привычек говорящего. В некоторых версиях программы значение вероятности для слова варьируется в зависимости от того, какое слово ему предшествует; это единственный вид информации «сверху—вниз», используемый программой. Все вышеупомянутое позволяет программе вычислить, какое слово с наибольшей вероятностью произнес говорящий, исходя из имеющихся звуковых данных. Но даже при этом DragonDictate больше полагается на ожидания, чем нормально слышащий человек. Когда я присутствовал при демонстрации программы, ее пришлось упрашивать отличить слово
Теперь, когда вы знаете, как продуцируются единицы речи, как они представлены в ментальном словаре, как они перестраиваются и обрабатываются прежде, чем появиться из наших губ, в конце этой главы вас ждет награда: вы узнаете, почему английское правописание не столь ненормально, как кажется на первый взгляд.
Конечно, на английское правописание можно пожаловаться за то, что оно якобы отражает звуки слов, но не делает этого в действительности. В жанре шутливых стихов этот факт обыгрывается с незапамятных времен, примером чему служат следующие вирши:
Джордж Бернард Шоу вел решительную борьбу за реформу английского алфавита, системы, по его словам, настолько нелогичной, что в соответствии с ней слово
Чтобы осознать годовую положительную разницу от использования 42-буквенного фонетического алфавита… нужно умножить количество минут в году на количество людей в мире, которые постоянно пишут английские слова, отливают шрифты, производят пишущие и печатающие механизмы, и к этому моменту общая сумма будет настолько астрономической, что вы осознаете, что стоимость написания даже одного звука двумя буквами обошлась нам в столетия ненужного труда. Новый английский алфавит в 42 буквы окупится в миллионы раз не только в течение часов, но в течение минут. Когда это будет уяснено, вся ненужная болтовня, касающаяся слов
Защищая английское правописание, я буду испытывать противоречивые чувства. Поскольку, хотя язык и является инстинктом, письмо им не является. Оно изобреталось всего несколько раз на протяжении истории, а алфавитное письмо, где один знак соответствует одному звуку, кажется, было изобретено всего однажды. В большинстве человеческих сообществ письменный язык отсутствовал, а там, где он имелся, он был унаследован или заимствован у сообщества изобретателей. Научить ребенка читать и писать — это кропотливый труд, и умение писать не предполагает тех качественных скачков вперед от учебного материала, которые мы наблюдали в случаях с Саймоном, Майелой, Джаббой и мышеедом из экспериментов в главах 3 и 5. И обучение не обязательно приводит к успеху. Неграмотность — результат недостаточного обучения — обычное явление во всем мире, но даже при достаточном обучении у 5–10 % населения имеется дислексия, что порождает трудности с обучением чтению и создает серьезную проблему даже в индустриально развитых странах.
Но хотя письмо — это искусственное изобретение, связующее зрение и язык, оно должно быть внедрено в языковую систему в специально отведенных местах, что придает ему крупицу логики. Во всех известных системах письма символы выражают только три вида языковых структур: морфемы, слоги и фонемы. Месопотамская клинопись, египетские иероглифы, китайские логограммы и японское письмо кандзи[92] зашифровывают морфемы. Письмо чероки, древне-кипрское и японское письмо кана[93] основаны на слогах. Все современные фонематические алфавиты, как выяснилось, происходят от системы, изобретенной жителями земли Ханаан около 1700 г. до н.э. Ни в одной системе письма нет символов для реальных звуковых единиц, которые могут быть идентифицированы на осциллоскопе или в спектрограмме, — фонем, произносимых в определенном контексте, или рассеченного пополам слога.
Почему же ни одна система письма так и не воплотила идеал Шоу — один символ для одного звука? Как однажды где-то сказал сам Шоу: «В жизни существуют две трагедии: одна — не получить то, чего жаждет сердце, а вторая — получить это». Мысленно вернитесь к принципам работы фонологии и коартикуляции. Идеальный в представлении Шоу алфавит предполагал бы появление различных гласных в словах
Очевидно, алфавиты не соответствуют и не должны соответствовать звукам, в лучшем случае они соответствуют фонемам, указанным в ментальном словаре. Реальные звуки будут разными в разных контекстах, поэтому чисто фонетическое написание только скрыло бы их глубинное сходство. Те звуки, что появляются на поверхностном уровне, можно предсказать благодаря фонологическим правилам, поэтому нет необходимости рыскать по странице с символами реальных звуков; читателю нужен только абстрактный образ слова, и он сможет при необходимости сам воссоздать звук. И действительно, для 84 % английских слов правописание полностью предсказуемо, исходя из стандартных правил. Более того, поскольку диалекты, разделенные временем и пространством, зачастую различаются больше всего в области фонологических правил, которые преобразуют единицы ментального словаря в произношение, правописание, соответствующее этим глубинным единицам, а не звукам, должно быть общим для многих диалектов. Слова с действительно странным правописанием (такие как:
Даже наименее предсказуемые аспекты правописания выдают скрытые языковые закономерности. Рассмотрим следующие пары слов, где одни и те же буквы получают разное произношение:
electric [ɪ'lektrɪk] electricity [ɪ'lek'trɪsətɪ]
declare [dɪ'kleə] declaration ['deklə'reɪʃn]
photograph ['fəʊtəgrɑːf] photography [fə'tɒgrəfɪ]
muscle ['mʌsəl] muscular ['mʌskjʊlə]
grade [greɪd] gradual [ˈgrədʒuəl]
condemn [kən'dem] condemnation ['kɒndem'neɪʃən]
history ['hɪstərɪ] historical [hɪ'stɒrɪkəl]
courage ['kʌrɪdʒ] courageous [kə'reɪdʒəs]
revise [rɪ'vaɪz] revision [rɪ'vɪʒən]
romantic [rəʊˈməntɪk] romanticize [rəʊˈməntɪsaɪz]
adore [ə'dɔː] adoration ['ədə'reɪʃn]
industry ['ɪndəstrɪ] industrial [ɪn'dʌstrɪəl]
bomb [bɒm] bombard [bɒm'bɑːd]
fact [fækt] factual [ˈfəktʃuəl]
nation ['neɪʃn] national ['neʃənəl]
inspire [ɪn'spaɪə] inspiration ['ɪnspɪ'reɪʃn]
critical ['krɪtɪkəl] criticize ['krɪtɪsaɪz]
sign [saɪn] signature ['sɪgnətʃə]]
mode [məʊd] modular ['mɒdjʊlə]
malign [mə'laɪn] malignant [mə'lɪgnənt]
resident ['rezɪdənt] residential ['rezɪ'denʃəl]
И вновь одинаковое правописание, несмотря на разницу в произношении, имеет определенную цель: оно указывает на то, что два слова имеют одну и ту же корневую морфему. Это свидетельствует о том, что английское правописание не полностью фонематическое; иногда буквы зашифровывают фонемы, но иногда последовательность букв точно указывает на морфему. И морфемное письмо гораздо полезнее, чем можно было бы предположить. В конце концов смысл чтения в том, чтобы понять текст, а не произнести его. Основанное на морфемах правописание может помочь читателю различить омофоны, такие как
Кое в чем система письма, основанная на морфемах, сослужила китайцам хорошую службу, несмотря на тот присущий ей недостаток, что читатель теряется, встречая новое или редкое слово. Носители диалектов, которые не понимают друг друга, могут читать одни и те же тексты (даже если слова из этих текстов они произносят на своих диалектах совершенно по-разному), а многие документы, написанные тысячи лет назад, может прочитать и современный человек. Марк Твен ссылался на такую же инертность в нашей романской системе правописания, когда говорил: «Они пишут Vinci, а произносят Vinchy (Винчи); иностранцы всегда пишут лучше, чем они произносят».
Конечно, английское правописание могло бы быть и лучше, чем оно есть. Но оно уже гораздо лучше, чем большинство людей о нем думает, поскольку системы письма не ставят своей задачей отразить реальные звуки, возникающие при разговоре, которые мы не слышим, но абстрактные языковые единицы, лежащие в их основе, именно те, что нам слышны.
| © 2024 Библиотека RealLib.org (support [a t] reallib.org) |