"ГЕДЕЛЬ, ЭШЕР, БАХ: эта бесконечная гирлянда" - читать интересную книгу автора (Хофштадтер Даглас Р.)
ГЛАВА X: Уровни описания и компьютерные системы
У ГЁДЕЛЕВОЙ СТРОЧКИ G и у фуги Баха есть одно и то же свойство: их можно понять на нескольких уровнях. Все мы знакомы с подобным явлением; иногда оно нас озадачивает, а иногда мы не видим в нем ничего особенного. Например, все мы знаем, что человеческие существа сделаны из огромного количества (около 25 триллионов) клеток и, следовательно, все, что мы делаем, может быть в принципе описано на клеточном — или даже на молекулярном — уровне. Большинство из нас воспринимает этот факт как нечто само собой разумеющееся. Когда мы идем к доктору, он смотрит на нас на более низком уровне, чем воспринимаем себя мы сами. Мы читаем о ДНК и «генетической инженерии», попивая при этом кофе. По-видимому, нам удалось примирить эти два несовместимых восприятия нас самих, просто разъединив их в сознании. Для нас практически невозможно соотнести собственное микроскопическое описание с восприятием себя как личности, и поэтому мы храним эти две разные картины в разных «отделениях» мозга. Изредка мы пытаемся соотнести эти два восприятия, спрашивая себя: «Как это так, что эти две совершенно разные вещи — не что иное, как один и тот же человек?»
Возьмите, например, последовательность образов на экране телевизора, показывающего улыбающуюся Мэрилин Монро. Глядя на эту последовательность, мы знаем, что на самом деле видим не женщину, а множество мерцающих точек на плоской поверхности. Однако в данный момент это нас совершенно не волнует. У нас в голове совмещаются две абсолютно разные картины того, что мы видим на экране, но это нас не смущает. Мы можем легко «выключить» одну из них и начать следить за другой и делаем это постоянно. Какая из них «реальнее»? Это зависит от того, кто вы такой: человек, собака, компьютер или телевизионный аппарат.
Одна из самых трудных задач, стоящих перед исследователями искусственного интеллекта — найти способ соединить эти два описания и создать систему, которая могла бы принимать один уровень описания и производить другой. Эта проблема хорошо иллюстрируется прогрессом в создании компьютерных программ, играющих в шахматы. В 1950-х и 1960-х годах считалось, что ключом к созданию хорошо играющей машины является ее умение заглянуть вперед в разветвляющуюся сеть возможных продолжений игры дальше, чем любой шахматный мастер. Однако, когда программы стали мало-помалу приближаться к этой цели, обнаружилось, что никакого скачка в качестве игры шахматных компьютеров не произошло, и они не обогнали человеческих экспертов. Фактом остается то, что по сегодняшний день шахматные мастера-люди все еще регулярно обыгрывают самые лучшие программы.
Объяснение этого факта давно уже опубликовано В 1940 году датский психолог Адриан де Грот исследовал то, как шахматные мастера, в отличие от новичков, оценивают позицию. Его исследования показали, что мастера воспринимают расположение фигур
Из этого следует, что в шахматных партиях повторяются некие типы ситуаций, некие определенные схемы и что именно эти схемы высшего уровня воспринимаются мастером. Он думает на
Это различие приложимо также и к другим видам интеллектуальной деятельности — например, к занятиям математикой. Способный математик обычно не обдумывает всяческие ложные пути к доказательству нужной теоремы, как это могли бы делать менее одаренные люди; скорее, он «нюхом чувствует» многообещающие пути и сразу направляется по ним.
Компьютерные шахматные программы, основанные на заглядывании далеко вперед, не научены думать на высшем уровне; стратегией таких машин была «грубая сила» просчета вариантов, в надежде таким образом сокрушить любое сопротивление. Однако оказалось, что эта стратегия не работает. Может быть, когда-нибудь и удастся создать такую программу, которая, основываясь только на грубой силе — умению считать варианты — действительно сможет обыгрывать лучших человеческих игроков. Однако это будет небольшим выигрышем в области интеллекта, по сравнению с открытием того, что важнейшей составляющей разума является его умение создавать многоуровневые описания сложных схем, таких, как шахматные доски, телевизионные экраны, печатные страницы или картины.
Обычно нам не приходится держать в уме больше одного уровня понимания ситуации. Более того, как мы уже сказали ранее, различные описания одной и той же системы бывают настолько далеки друг от друга концептуально, что у нас не возникает проблемы одновременного восприятия обоих; они просто хранятся в разных мысленных отделениях. Трудности возникают тогда, когда одна и та же система допускает два или более описаний, в чем-то похожих друг на друга. Тогда нам бывает трудно, думая о системе, не смешивать различные уровни — и при этом мы легко можем запутаться.
Вне сомнения, это происходит, когда мы думаем о нашей собственной психологии — скажем, когда мы пытаемся понять мотивы различных человеческих поступков. В структуре человеческого разума есть множество уровней — безусловно, это система, которую мы пока понимаем недостаточно хорошо. Существуют сотни соперничающих друг с другом теорий, объясняющих различное поведение; они основаны на предположениях о том, насколько глубоко в этой иерархии уровней расположены те или иные психологические «силы». Поскольку в настоящее время мы используем почти один и тот же язык для описания различных уровней, это приводит к немалой путанице и, наверняка, к рождению множества ложных теорий. Например, мы говорим о стимулах — сексе, власти, славе, любви — понятия при этом не имея, где именно в структуре человеческого интеллекта они зарождаются. Я не буду останавливаться на этом подробно; скажу лишь, что наше непонимание того, кто мы есть, безусловно связано с тем фактом, что мы состоим из большого количества уровней и используем один и тот же язык для описания нас самих на разных уровнях.
Существует еще одно место, где многие уровни описания сосуществуют в единой системе и все уровни концептуально близки один к другому. Я имею в виду компьютерные системы. Работающую компьютерную программу можно рассматривать на нескольких уровнях. На каждом уровне описание дается на языке вычислительных машин, что делает все описания в какой-то мере схожими — в то же время между нашим восприятием разных уровней есть крайне важные различия. На низшем уровне описание настолько сложно, что его можно сравнить с описанием образа на экране телевизора в виде набора точек; однако для определенных целей нужен именно такой взгляд на вещи. На высшем уровне описание представлено в форме крупных
 |
Чтобы предмет нашего разговора не стал слишком абстрактным, обратимся к конкретным фактам из области вычислительной техники; для начала бросим взгляд на то, что представляет собой компьютерная система на низшем уровне. Низший уровень? Не совсем, конечно — но я не буду здесь говорить об элементарных частицах, так что для нас это будет низшим уровнем.
В основании компьютерной системы находится
00X0XXX0X00XX00X0XXXXXX0XX00XXX0000
— слово из 36 битов —
Вы можете называть эти положения «вверх» и «вниз», или «x» и «o», или «1» и «0». Последнее — общепринятое название, оно вполне адекватно, но может запутать читателя, заставив его думать, что на самом деле в памяти компьютера хранятся числа. Это неверно. У нас столько же оснований думать о наборе из тридцати шести битов, как о числе, как и считать, что два четвертака — это цена мороженого. Так же, как деньги могут быть использованы по-разному так и слово в памяти может выполнять разные функции. Строго говоря, иногда эти тридцать шесть битов действительно могут представлять число в двоичной записи. В другой раз они могут представлять тридцать шесть точек на экране телевизора, или же несколько букв текста. Наша интерпретация слова в памяти целиком зависит от той роли, которую это слово играет в использующей его программе. Разумеется, оно может играть несколько ролей — как нота в каноне.
Существует еще одна интерпретация слова, о которой я пока не упоминал слово может интерпретироваться как
Откуда компьютер знает, в какой момент надо выполнять ту или иную команду? Об этом заботится ЦП. В нем есть специальный указатель, который указывает (то есть хранит соответствующий адрес) на следующее слово-команду. ЦП извлекает это слово из памяти и копирует его на специальное слово в самом ЦП. (Слова в ЦП обыкновенно называют не словами, а
ДОБАВИТЬ слово, указанное в команде, к регистру. (В этом случае данное слово интерпретируется как число.)
НАПЕЧАТАТЬ слово, указанное в команде, в виде букв. (В этом случае данное слово интерпретируется не как число, а как строчка букв.)
ПЕРЕЙТИ к слову, указанному в команде. (В этом случае ЦП интерпретирует данное слово, как следующую команду.)
Если первоначальная команда не содержит явного указания поступить иначе, ЦП просто обращается к следующему слову и интерпретирует его, как команду. Иными словами, ЦП предполагает, что он должен двигаться вдоль по «улице» последовательно, как почтальон, интерпретируя слово за словом как команды. Однако это последовательное движение может быть прервано некоторыми командами, такими как, например, ПЕРЕХОД.
Вы только что прочитали очень краткий обзор
Надо сказать, что первоначально программирование делалось на еще более низком уровне, чем машинный язык: соединялись определенные провода, так что нужные операции как бы «телеграфировались» машине. Этот процесс настолько примитивен по современным понятиям, что теперь его трудно себе вообразить. И все же люди, впервые это сделавшие, безусловно испытали такую же радость, какую когда-либо чувствовали создатели современных компьютеров…
Перейдем теперь на более высокую ступень иерархии уровней описания программ — уровень
Возможно, что самое важное в языке ассемблера — не его отличие от машинного языка, которое не столь уж велико, но сама идея того, что программы вообще могут быть написаны на различных уровнях. Ведь компьютерная аппаратура построена так, чтобы «понимать» программы на машинном языке — последовательности битов — а не буквы и не числа в десятичной записи! Что происходит, когда в эту аппаратуру вводится программа на языке ассемблера? Это напоминает попытку заставить клетку узнать бумажку с записанном буквами нуклеотидом, вместо самого нуклеотида со всеми его химическими компонентами. Что делать клетке с этой бумажкой? Что делать компьютеру с программой на языке ассемблера?
Здесь мы подошли к главному: возможно написать на машинном языке
На следующем уровне иерархии крайне важная идея о том, что сами компьютеры можно заставить переводить программы с высших на низшие уровни, развивается еще далее. В начале 1950-х годов, когда программа ассемблера уже использовалась в течение нескольких лет, было подмечено, что существуют несколько характерных структур, появляющихся в программе за программой. По-видимому, так же как и в шахматах, это были некие характерные структуры, естественно возникающие тогда, когда люди пытаются найти алгоритмы — точные описания процессов, которые они хотят осуществить. Иными словами, кажется, что в алгоритмах есть некие компоненты высшего уровня, при помощи которых они могут быть описаны с большей легкостью и эстетизмом, нежели на весьма ограниченном машинном языке или языке ассемблера. Обычно такой компонент высшего уровня в алгоритме представляет собой не одну-две машинных команды, но целый конгломерат; при этом эти команды не обязательно соседствуют в памяти. Подобный компонент может быть представлен на языке высшего уровня как некое единство, или блок.
Оказывается, что кроме стандартных блоков (только что открытых компонентов, из которых могут быть построены все алгоритмы), почти все программы содержат еще большие блоки — так сказать, суперблоки. Эти суперблоки меняются от программы к программе, в зависимости от типа задания на высшем уровне, которое данная программа должна выполнить. Мы уже говорили о суперблоках в главе V, употребляя общепринятые названия, «подпрограммы» и «процедуры». Ясно, что если бы удалось
Были изобретены также
Между принципом работы интерпретаторов и компиляторов есть одно интересное различие. Компилятор берет входные данные (к примеру, законченную программу на Алголе) и производит некий результат (длинную последовательность команд на машинном языке). На этом его работа закончена и результат вводится в компьютер для обработки. Интерпретатор, напротив работает непрерывно, пока программист вводит одно за другим высказывания ЛИСПа, каждое из них немедленно выполняется. Однако это не означает что каждое высказывание сначала переводится и затем выполняется — тогда интерпретатор был бы всего лишь построчным компилятором. Вместо этого в интерпретаторе операции считки новой строчки, ее «понимания» и выполнения переплетены — они происходят одновременно.
Поясню эту идею немного подробнее. Как только новая строчка ЛИСПа вводится в интерпретатор, он пытается ее обработать. Это означает, что интерпретатор начинает действовать, и в нем выполняются некие машинные команды. Какие именно — это зависит, разумеется, от данного высказывания ЛИСПа. Внутри интерпретатора много команд типа ПЕРЕХОД, так что новая строчка ЛИСПа может заставить контроль двигаться довольно сложным путем вперед, назад, затем опять вперед и т. д. Таким образом, каждое высказывание ЛИСПа превращается в некий «маршрут» внутри интерпретатора, и следование по этому маршруту приносит нужный эффект.
Иногда бывает полезно интерпретировать высказывания ЛИСПа как некие блоки данных, которые постепенно вводятся в непрерывно действующую программу машинного языка (интерпретатор ЛИСПа). Думая об этом таким образом, вы по-иному видите отношения между программой, написанной на языке высшего уровня, и исполняющей эту программу машиной.
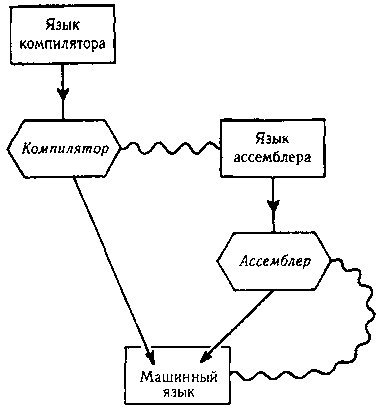
Разумеется, компилятор, будучи программой, должен быть сам написан на каком-либо языке. Первые компиляторы были созданы на языке ассемблера вместо машинного языка; таким образом полностью использовались преимущества подъема на одну ступеньку над машинным языком. Краткое описание этих довольно сложных понятий представлено на рис. 58.
 |
По мере того, как программирование становилось более изощренным, было замечено, что частично законченный компилятор может быть использован для того, чтобы компилировать собственные продолжения. Иными словами, когда создано определенное минимальное ядро компилятора, это минимальное ядро может переводить большие компиляторы на машинный язык, пока таким образом не создастся окончательный, полный компилятор. Этот процесс известен под именем «самонастройки»; он несколько напоминает достижение ребенком критического уровня владения своим родным языком, после чего его словарь и грамматическое мастерство растут как снежный ком, так как для изучения языка он может
Языки компиляторов обычно не отражают структуры машин, на которых будут выполняться написанные на этих языках программы. Это одно из их основных преимуществ по сравнению с весьма специализированными языками ассемблера и машинным языком. Разумеется, когда программа на языке компилятора переводится на язык машины, получается программа, зависящая от машины. Таким образом, возможно описать программу, которая исполняется либо зависящим от машины путем, либо не зависящим, подобно тому, как мы можем описать абзац в книге по его содержанию (описание, не зависящее от издания) или по номеру страницы и его расположению на ней (описание, зависящее от издания).
Пока программа работает хорошо, то, как мы ее описываем и что мы о ней думаем, не столь важно. Но как только возникают неполадки, становится важным умение увидеть программу на разных уровнях. Если, например, компьютеру дана задача в какой-то момент разделить на нуль, он остановится и сообщит пользователю о возникшей проблеме, указав при этом, в каком месте программы произошло это неприятное событие. Однако эти детали часто сообщаются на более низком уровне, чем тот, на котором написана сама программа. Вот три параллельных описания забуксовавшей программы:
Уровень машинного языка:
«Выполнение программы прекратилось по адресу 1110010101110111»
Уровень языка ассемблера:
«Выполнение программы прекратилось, когда она дошла до команды РАЗДЕЛИТЬ».
Уровень языка компилятора:
«Выполнение программы прекратилось в момент оценки алгебраического выражения „(А + B)/Z“».
Одна из основных задач программистов (людей, которые создают компиляторы, интерпретаторы, ассемблеры и другие программы, которые затем используются многими людьми) — это создание находящих ошибки подпрограмм. Необходимо, чтобы информация, которую эти подпрограммы выдают пользователю, в чьей программе обнаружен дефект, представляла бы описание проблемы на высшем, а не на низшем, уровне. Интересно, что если сбой обнаруживается в генетической «программе» (например, мутация), то происходит обратное, ошибка бывает заметна только на
В современных компьютерных системах есть несколько других уровней иерархии. Например, некоторые системы — часто называемые «микрокомпьютерами» — используют еще более рудиментарные команды на машинном языке, чем добавка числа в памяти к числу в регистре. Пользователь должен сам решать, какой тип команд на обычном машинном языке он хочет запрограммировать; он «микропрограммирует» эти команды в терминах имеющихся у него «микрокоманд» После этого разработанные им команды на языке высшего уровня могут быть включены в схему компьютера и стать частью аппаратуры, хотя это и не обязательно. Подобное микропрограммирование позволяет пользователю спуститься немного ниже уровня обычного машинного языка. Одним из следствий этого является то, что какой-либо компьютер одной фирмы может, путем микропрограммирования, быть снабжен такой аппаратурой, что она повторяет машинные команды другого компьютера той же (или даже иной) фирмы. При этом говорится, что компьютер с микропрограммой имитирует другой компьютер.
Далее, у нас имеется уровень
Рассмотрим первую телефонную систему. Александр Грэхем Белл мог позвонить своему ассистенту в соседнюю комнату: электронная передача голоса! Это сравнимо с простым компьютером без операционной системы: электронные вычисления!
Рассмотрим теперь современную телефонную систему. У вас есть выбор, с каким телефоном соединиться; к тому же, можно отвечать на многие звонки одновременно. Вы можете добавить код и соединиться с другими районами. Вы можете позвонить прямо или через оператора; так, что звонок будет оплачен вашим собеседником или по вашей кредитной карточке. Можно говорить с одним человеком или сразу с несколькими; можно «перенаправить» или проследить звонок. Существует сигнал «занято», сигнал, говорящий вам, что набранный номер не является «хорошо сформированным» и сигнал, говорящий вам, что вы набирали номер слишком долго. Вы можете установить местный коммутатор, соединяющий несколько телефонов, — и так далее, и тому подобное. Это удивительный список, если подумать, сколько возможностей он представляет, в особенности, по сравнению с былым чудом «голого» телефона. Вернемся теперь к компьютерам: сложные операционные системы выполняют примерно те же операции направления трафика и переключения уровней по отношению к пользователям и их программам. Мы можем быть практически уверены в том, что у нас в мозгу происходят некие параллельные процессы, одновременная обработка многих стимулов; решения о том, что должно выйти на первый план и на какое время; мгновенные «перерывы» из-за неожиданных событий и критических положений и так далее.
Многие уровни сложной компьютерной системы, взятые вместе, облегчают пользователям их работу, позволяя им не думать о процессах, происходящих на низших уровнях (которые, скорее всего, для них совершенно неважны). Пассажир в самолете обычно не интересуется уровнем горючего в баках, скоростью ветра, количеством куриных крылышек, которые будут поданы на ужин пассажирам, или воздушным трафиком около места назначения. Все это — дело служащих на разных уровнях иерархии авиакомпании; пассажир же хочет только одного: чтобы его доставили из одного места в другое. Только когда случается что-нибудь непредвиденное, например, потеря багажа, пассажир понимает, с какой запутанной системой уровней он имеет дело.
Одной из основной целей в нашем стремлении к высшим уровням всегда было желание сообщать компьютеру о том. чего мы от него хотим, самым естественным для нас образом. Безусловно, конструкции высшего уровня в языках компиляторах ближе к категориям, в которых обычно думают люди, чем конструкции низшего уровня, такие, как в машинных языках. Но в этом стремлении к легкости общения с компьютерами мы обычно забываем об одном из аспектов «естественности», — а именно, том факте, что общение между людьми имеет намного меньше ограничений, чем общение между человеком и машиной. Например, мы зачастую произносим бессмысленные словосочетания, ища, как бы получше выразить свою мысль, кашляем в середине фразы, перебиваем друг друга, используем двусмысленные описания и «неправильный» синтаксис, придумываем выражения и искажаем смысл — но наши сообщения обычно все же достигают цели. В языках программирования, напротив синтаксис должен быть стопроцентно строгим, в них не должно быть двусмысленных выражений и конструкций. Интересно, что печатный эквивалент кашля разрешен, но только если он предварен условным знаком (например, словом КОММЕНТАРИЙ), после него также должен иметься условный знак (например, точка с запятой). Ирония в том, что эта небольшая уступка гибкости создает свои проблемы: если точка с запятой (или любой другой условный знак, отмечающий конец комментария) встречается
Представьте, что в программе определена процедура под названием ПОНИМАНИЕ, и эта процедура затем вызвана семнадцать раз. Если в восемнадцатый раз это слово ошибочно написано ПОМИНАНИЕ, горе программисту! Компилятор взбунтуется и напечатает весьма неприятное послание ОШИБКА, сообщая, что он никогда не слыхал ни о каком ПОМИНАНИИ. Часто, когда компилятор обнаруживает подобную ошибку, он пытается продолжить работу, но из-за отсутствия у него поминания, он не может понять, что имел в виду программист. На самом деле, он может даже вообразить, что тот имел в виду нечто совершенно другое, и начать действовать согласно этой ошибочной интерпретации. В результате, остальная программа будет усеяна посланиями «ошибка», потому что компилятор — а не программист — запутался. Вообразите, какая путаница получится, если, переводя с английского на русский, переводчик услышит фразу по-французски и попытается переводить остальной английский текст, как французский! Компиляторы часто запутываются таким жалким образом.
Может быть, это звучит как приговор компьютерам, — но я вовсе не имел это в виду. В некотором смысле, такое положение вещей необходимо. Если подумать, для чего обычно используются компьютеры, становится ясно, что они выполняют весьма определенные и точные задания, которые слишком сложны для людей. Чтобы мы могли доверять компьютерам, необходимо, чтобы они совершенно точно, без следа двусмысленности, понимали, что от них требуется. Необходимо также, чтобы компьютер делал не больше и не меньше того, что ему приказано. Если между компьютером и программистом стоит программа, предназначенная угадывать, чего тот хочет или имеет в виду, то весьма вероятно, что, когда программист попытается сообщить машине задачу, она будет понята совершенно неверно. Таким образом важно, чтобы программы высшего уровня хотя и удобные для людей, тем не менее были бы недвусмысленными и точными.
Несмотря на это, возможно создать язык программирования который допускает некоторый тип неточности и программу, переводящую его на низшие уровни. Можно сказать, что программа-переводчик при этом будет пытаться интерпретировать нечто, сделанное «вне правил языка». Но если в языке допускаются некие «нарушения» правил, подобные нарушения уже нельзя назвать настоящими нарушениями, поскольку они включены в правила! Если программисту разрешено допускать определенный тип ошибок, он может использовать эту черту, зная, что при этом он оперирует строго в рамках правил, несмотря на видимость обратного. Иными словами, если пользователь знает о всех трюках, делающих программу-переводчика более гибкой и удобной для пользования, то он знает и предел, который он не может перейти; следовательно, ему эта программа все равно кажется жесткой и негибкой, хотя она и дает ему гораздо большую свободу по сравнению с ранними версиями, не включавшими «автоматическую компенсацию человеческих ошибок.»
По отношению к «эластичным» языкам подобного типа может быть две альтернативы: (1) пользователь знает о встроенных в язык и в программу-переводчика уступках; (2) пользователь о них не знает. В первом случае, язык может быть использован для точного сообщения программ, поскольку программист может предсказать, как компьютер будет интерпретировать программы, написанные на этом языке. Во втором случае, в языке есть скрытые черты, могущие выкинуть что-нибудь непредсказуемое с точки зрения пользователя, не знающего о том, как работает программа-переводчик. Результатом этого могут быть грубые ошибки в интерпретации программы, поэтому такой язык не годится для использования компьютеров за их быстроту и надежность.
На самом деле, есть и третья альтернатива; (3) пользователь знает о встроенных в язык и в программу-переводчик отклонениях от правил, но их так много и они взаимодействуют таких сложным путем, что что он не может предсказать, как будут интерпретированы программы. Это может быть сказано о человеке, написавшем переводящую программу; он, разумеется, знает ее структуру как никто другой — и все же он не может предсказать того, как она будет реагировать на данный тип необычной конструкции.
Одна из основных областей исследования в сегодняшней науке об искусственном интеллекте называется
Удивительно, насколько прогресс в исследовании компьютерной техники (и в частности, искусственного интеллекта) связан с развитием новых языков. В последнее десятилетие возникла ясная тенденция: воплощать новые открытия в новых языках. Один из ключей к пониманию и созданию интеллекта лежит в постоянном развитии и улучшении языков, описывающих процессы манипуляции символами. На сегодняшний день имеется около трех-четырех дюжин экспериментальных языков, созданных исключительно для исследований по искусственному интеллекту. Важно понимать, что любая программа, написанная на одном из этих языков, в принципе может быть переведена на языки низших уровней, хотя это и потребовало бы от людей огромных усилий; получившаяся программа была бы такой длинной, что она оказалась бы за пределами человеческого понимания. Это не означает, что каждый высший уровень увеличивает потенциал компьютера; весь этот потенциал уже существует в наборе команд машинного языка. Просто новые понятия на языках высшего уровня по самой своей природе наводят на мысль о новых путях и перспективах.
«Пространство» всех новых программ настолько обширно, что никто не может представить себе всех возможностей. Каждый язык высшего уровня предназначен для исследования определенных районов «программного пространства», таким образом, используя данный язык, программист оказывается в соответствующем районе. Язык не
Программирование на разных языках подобно сочинению музыкальных произведений в различных тональностях, особенно если вы работаете на клавиатуре. Если вы уже выучили или написали произведения во многих ключах, каждая клавиша будет иметь для вас свою собственную эмоциональную окраску. Некоторые мелодии кажутся естественными в одном ключе, но неловкими в другом. Таким образом, ваше направление определяется выбором тональности. В некотором роде, даже энгармонические тональности, такие как до-диез и ре-бемоль, весьма отличаются по настроению. Это говорит о том, что система нотации может играть важную роль в том, как будет выглядеть конечный продукт.
«Стратифицированная» схема искусственного интеллекта показана на рис. 59; внизу лежат компоненты аппаратуры, такие, как транзисторы, а на вершине расположены «думающие программы». Эта иллюстрация взята из книги «Искусственный интеллект» Патрика Генри Винстона (Patrick Henry Winston, «Artificial Intelligence»), она представляет собой общепринятый среди специалистов взгляд на искусственный интеллект. Хотя я согласен с идеей, что ИИ должен быть стратифицирован подобным образом, мне не кажется, что с таким небольшим количеством уровней возможно получить думающие программы.
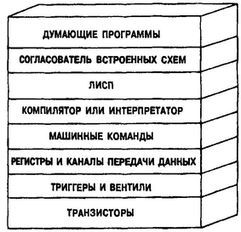 |
Между уровнем машинного языка и уровнем, на котором может быть достигнут настоящий интеллект, должна, по-моему убеждению, лежать еще дюжина (или даже несколько дюжин!) уровней, каждый следующий из которых, базируясь на предыдущем, в то же время был бы более гибким. Сейчас мы с трудом можем себе вообразить, как это будет выглядеть…
Схожесть уровней в компьютерной системе может привести к странному их смешению. Однажды я был свидетелем того, как пара моих приятелей — оба новички в компьютерном деле — забавлялись на терминале с программой «PARRY». PARRY — это печально известная программа, симулирующая параноика весьма простеньким образом: она выдает заранее заготовленные английские фразы, выбранные из широкого репертуара. Правдоподобие достигается тем, что программа может определить, какие именно «заготовки» могут звучать разумно в ответ на фразы, введенные в компьютер человеком.
В какой-то момент PARRY надолго задумалась, и я объяснил друзьям, что задержка, скорее всего, связана с большой нагрузкой на систему разделения времени. Я сказал им, что они могут узнать, сколько человек подключены к системе в данный момент; для этого нужно напечатать специальный символ «контроль», который пойдет прямо в операционную систему, минуя PARRY. Один из моих приятелей нажал на соответствующую клавишу, после чего некие данные о статусе операционной системы отпечатались на экране поверх фраз PARRY. При этом PARRY об этом понятия не имела, поскольку это программа, «понимающая» только в скачках и пари, но ничего не знающая об операционных системах, терминалах и специальных символах контроля. Для моих друзей, однако, PARRY и операционная система были одним и тем же — «компьютером», загадочным, аморфным, далеким существом, которое отвечало на то, что они печатали. Так что для них было вполне естественно, когда один из них с улыбкой напечатал «Почему вы пишете поверх того, что на экране?» Идея о том, что PARRY может ничего знать об операционной системе, при помощи которой она действует, была непонятна моим друзьям. Идея что «мы» знаем все о «нас самих» казалась им настолько естественной из их опыта людских контактов, что они просто распространили ту же идею на компьютер — в конце концов, он же был достаточно умен, чтобы «разговаривать» с ними по-английски! Их вопрос похож на то, как если бы вы спросили кого-нибудь: «Почему вы сегодня производите так мало красных кровяных шариков?» Люди не знают об этом уровне — «уровне операционных систем» — их тела.
Главная причина этого смешения уровней была в том, что общение со всеми уровнями компьютерной системы происходило на одном и том же экране, на одном и том же терминале. Хотя наивность моих друзей может показаться преувеличенной, даже опытные компьютерные специалисты часто допускают подобные ошибки, когда несколько уровней сложной системы бывают одновременно представлены на одном и том же экране. Они забывают, кто их «собеседник» и печатают что-то, не имеющее смысла на данном уровне, хотя и вполне приемлемое на другом. Может показаться, что хорошо было бы заставить саму систему сортировать уровни — интерпретировать команды согласно тому, какая из них «имеет смысл». К несчастью, подобная интерпретация требует от машины немалой толики здравого смысла и совершенного знания намерений программиста, а это требует настолько развитого искусственного интеллекта, которого на сегодняшний день у компьютеров нет.
Путаница может также возникнуть из-за того, что одни уровни гибки, а другие — строги и жестки. Например, в некоторых компьютерах есть замечательные программы-редакторы, которые позволяют переводить куски текста из одного формата в другой, почти так же, как жидкость может быть перелита из одного сосуда в другой. Узкую страницу можно превратить в широкую, и наоборот. При такой мощи можно ожидать, что поменять шрифт, скажем, на курсив, также не представит никакого труда. Однако у программы может быть только один шрифт, что делает подобные изменения невозможными. Бывает также, что нужный шрифт можно получить на экране, но не на принтере — или наоборот. Долго работая с компьютерами, легко избаловаться и считать, что программированию должно поддаваться все; не должно быть негибких принтеров, имеющих только один шрифт, или даже конечный набор шрифтов, шрифты должны определяться пользователем! Но достигнув этой степени гибкости, мы начинаем расстраиваться, что принтер не печатает разноцветными чернилами на бумаге любой формы и размера или что он не чинит сам себя…
Проблема в том, что в какой-то момент вся эта гибкость должна, используя фразу из главы V, «коснуться дна». Должен существовать жесткий уровень аппаратуры, на котором основано все остальное. Он может быть спрятан под гибкими уровнями так глубоко, что немногие пользователи чувствуют ограничения, налагаемые аппаратурой — однако эти ограничения неизбежны.
В чем именно состоит разница между
В нас, человеческих существах, тоже есть аспекты «аппаратуры» и «программного обеспечения» и разница между ними для нас настолько естественна, что мы перестаем ее замечать. Мы привыкли к негибкости нашей физиологии: то, что мы не можем усилием воли вылечить себя от всех болезней или заставить расти у нас на голове волосы любого цвета — лишь два простых примера. Однако мы можем «перепрограммировать» наш мозг, чтобы оперировать в рамках новых понятий. Удивительная гибкость интеллекта кажется почти несовместимой с тем фактом, что наш мозг сделан из «аппаратуры», подчиняющейся строгим правилам, аппаратуры, которую невозможно изменить. Мы не можем заставить наши нейроны реагировать быстрее или медленнее, не можем «поменять проводку» у себя в мозгу, не можем изменить внутренность нейрона — короче, у нас нет
Однако существуют аспекты нашего мышления, не поддающиеся контролю. Мы не можем, по желанию, стать сообразительнее; не можем выучить новый язык так быстро, как бы нам хотелось; не можем заставить себя думать о нескольких вещах сразу и так далее. Это знание о нашей природе столь изначально, что его даже трудно заметить; это все равно, что постоянно сознавать, что вокруг нас — воздух. Мы никогда не думаем о возможной причине подобных «дефектов» нашего интеллекта — устройстве нашего мозга. Основная цель этой книги — предложить пути примирения между аппаратурой — мозгом и программным обеспечением — интеллектом.
Мы видели, что в компьютерных системах есть множество довольно четко определенных уровней, и что работающая программа может быть описана в терминах любого из них. Таким образом, существуют не только низший и высший уровни — есть самые различные степени низкого и высокого. Типичны ли промежуточные ступени для всех систем с низшими и высшими уровнями? Рассмотрим для примера систему, аппаратурой которой является земная атмосфера, а программным обеспечением — погода. Проследить за движением всех молекул одновременно было бы способом «понимания» природы на весьма низком уровне — что-то вроде работы с огромной сложной программой на машинном языке. Ясно, что эта задача лежит далеко за пределами человеческих возможностей. Однако у нас есть наш особый, человеческий способ наблюдения за погодными явлениями и их описания. Мы воспринимаем природные явления на высоком уровне — крупными блоками, такими, как дождь, снег, туман, ураганы, холодные фронты, времена года, атмосферное давление, ветры, течения, кучевые облака, грозы, уровни инверсии и так далее. Во всех этих явлениях участвует астрономическое число молекул, которые каким-то образом действуют вместе, давая крупномасштабный эффект. Этот метод сравним с использованием для анализа погоды языка компилятора.
Существует ли аналог исследованию погоды при помощи промежуточных языков, таких, как язык ассемблера? Бывают ли, к примеру, очень маленькие местные «мини-штормы», как те крохотные смерчи, крутящие пыльные столбы максимум пару метров в диаметре? Является ли порыв ветра блоком промежуточного уровня, играющим роль в создании погодных явлений более крупного масштаба? Или же не существует практического способа использовать наши знания о подобных явлениях с тем, чтобы получить более полное объяснение погоды?
Тут возникают еще два вопроса. Первый такой: «Может ли быть, что погодные явления, воспринимаемые нами как смерчи и засухи, на самом деле — лишь явления промежуточных уровней, составляющие часть каких-то более общих, медленно протекающих явлений?» В таком случае, погодные явления настоящего высшего уровня были бы глобальными, и их время измерялось бы по геологической шкале. Ледниковый период был бы погодным событием такого высшего уровня. Второй вопрос: «Есть ли такие погодные явления промежуточного уровня, которых люди до сих пор не замечали, но которые могли бы дать нам более глубокое понимание погоды?»
Последнее предположение может звучать, как чистая фантазия, но это не совсем так. Стоит только взглянуть на точнейшую из точных наук, физику, чтобы найти необычные примеры систем, описанных в терминах взаимодействия таких «частей», которые сами по себе невидимы. В физике, как и в любой другой дисциплине,
Некоторые системы, изучаемые в физике, представляют собой контраст по сравнению с относительно простым атомом. В таких системах взаимодействие частей необычайно сильно, в результате чего они проглатываются большей системой и частично или полностью теряют свою индивидуальность. Примером является ядро атома, которое обычно описывается как «набор протонов и нейтронов». Но силы, удерживающие вместе частицы, составляющие ядро, так велики, что эти частицы становятся совершенно непохожи на самих себя в «свободной» форме (то есть когда они находятся вне ядра). На самом деле, ядро во многих смыслах более похоже на единую частицу, чем на набор взаимодействующих частиц. Когда ядро расщепляется, при этом обычно освобождаются протоны и нейтроны, но также и другие частицы, такие как пи-мезоны и гамма-лучи. Находятся ли все эти частицы внутри ядра до его расщепления, или же они — что-то вроде «искр», летящих при расщеплении ядра? Возможно, что искать ответа на подобный вопрос не имеет смысла. На уровне физики частиц разница между возможностью «высекать искры» и действительным наличием субчастиц не столь ясна.
Таким образом, ядро — это система, «части» которой, хотя они и невидимы внутри системы, могут быть извлечены и сделаны видимыми. Однако есть и более патологические случаи, такие, как протон и нейтрон, взятые как системы. Существует предположение, что каждый из них состоит из тройки «кварков» — гипотетических частиц, которые могут соединяться по две или по три, образуя при этом многие из известных основных частиц. Однако взаимодействие между кварками настолько сильно, что их не только невозможно увидеть внутри протонов и нейтронов, но и невозможно извлечь оттуда! Таким образом, хотя кварки помогают теоретически объяснить некоторые свойства протонов и нейтронов, их собственное существование, возможно, никогда не будет установлено с достоверностью. Здесь перед нами — антипод «почти разложимой системы», система, которую скорее можно назвать «почти неразложимой». Интересно, однако, что теория протонов и нейтронов (и других частиц), основанная на «модели кварков», дает хорошее количественное объяснение многих экспериментальных результатов, касающихся частиц, предположительно составленных из кварков.
В главе V мы обсуждали то, как ренормализованные частицы возникают из своих голых центров в результате рекурсивно накапливающихся взаимодействий с виртуальными частицами. Ренормализованную частицу можно рассматривать либо как это сложное математическое построение, либо как некий «бугорок», чем она и является физически. Одно из самых странных и впечатляющих последствий этого способа описания частиц — это объяснение, которое оно дает знаменитому явлению сверхпроводимости (свободному от сопротивления течению электронов в некоторых твердых телах при очень низких температурах).
Оказывается, что электроны в твердых телах ренормализованы в результате их взаимодействия с некими странными квантами вибраций, называемыми
Здесь есть несколько уровней частиц: сама куперова пара, пара составляющих ее поляронов с противоположным спином, электроны и фотоны из которых составлены поляроны; внутри электронов — виртуальные фононы и позитроны… и так далее, и тому подобное. Мы можем смотреть на каждый уровень и воспринимать происходящие там явления согласно нашему пониманию лежащих ниже уровней.
Точно так же, к счастью, нам не нужно знать о кварках всего, чтобы понимать многое в поведении частиц, составной частью которых они могут быть. Специалист по ядерной физике может разрабатывать теории о ядрах, основанные на протонах и нейтронах, и игнорировать как теории о кварках, так и теории, оспаривающие последние. Ядерный физик работает с
Хотя некоторая «утечка» между иерархическими уровнями наук присутствует всегда, и химик не может полностью игнорировать низшие уровни физики, или биолог — полностью игнорировать химию, утечки между далекими уровнями почти не происходит. Именно поэтому мы можем понимать других людей, не имея при этом глубокого понимания модели кварков, структуры ядра, природы орбит электронов, химических связей, структуры белков, органоидов в клетках, путей межклеточного сообщения, физиологии различных органов человеческого тела, или сложных взаимодействий между органами. Все, что нам необходимо, — это блочная модель действия высших уровней; и, как мы все знаем, подобные модели весьма реалистичны и успешны.
Однако у блочной модели есть и значительная негативная сторона; обычно она не дает точных предсказаний. Это значит, что хотя блочные модели спасают нас от невыполнимой задачи воспринимать людей как набор кварков (или того, что в них имеется на низшем уровне), они дают нам только вероятностные оценки того, как другие люди чувствуют, реагируют на наши слова и поступки и так далее. Короче, используя блочную модель, мы приносим в жертву детерминизм и выигрываем в простоте. Несмотря на то, что мы не знаем, как люди среагируют на наш анекдот, мы все же рассказываем его; при этом мы скорее ожидаем, что они засмеются (или не засмеются), чем, скажем, полезут на ближайший столб. (Конечно, мастер дзена запросто мог бы сделать именно это!) Блочная модель определяет «интервал» возможного поведения и вероятность того, что определенное поведение будет лежать в той или иной области этого интервала.
Эти идеи могут быть приложены не только к сложным физическим системам, но и к компьютерам. Известно высказывание: «Компьютеры могут делать только то, что им приказано». В каком-то смысле это верно, но при этом не учитывается следующий факт: последствия ваших инструкций неизвестны вам заранее, поэтому поведение компьютера может быть так же удивительно и непредсказуемо для вас, как и поведение человека. Обычно вам заранее известен тот приблизительный
Это старое высказывание неверно и в другом смысле. Дело в том, что, программируя на языках все высших уровней, вы все с меньшей и меньшей точностью можете сказать, что именно вы приказываете компьютеру! Многие прослойки переводов могут отделять «передний конец» сложной программы от действительных команд на машинном языке. На уровне, на котором вы думаете и программируете, ваши высказывания могут быть более похожи на утверждения и предложения, чем на команды. При этом внутренняя «возня», вызванная вводом высказывания высшего уровня, обычно остается для вас невидима, так же, как, когда вы едите бутерброд, вы не думаете о пищеварительных процессах, которые при этом начинаются у вас внутри.
Так или иначе, мнение, что «компьютеры могут делать только то, что им приказано», впервые высказанное лэди Лавлэйс в ее знаменитых мемуарах, настолько распространено и так связано с мнением о том, что «компьютеры не могут думать», что мы вернемся к нему в следующих главах, когда сможем обсудить этот вопрос на более высоком уровне.
Системы, построенные из многих частей, бывают двух типов. Первый их них характеризуется тем, что поведение одних частей аннулирует поведение других. В подобных системах не столь важно, что делается на низшем уровне, поскольку результатом любых происходящих там событий будет почти одинаковое поведение высшего уровня. Примером такой системы может служить баллон с газом, молекулы которого сталкиваются друг с другом в результате множества сложных микроскопических процессов; однако макроскопическое целое — это стабильная система в спокойном состоянии, в которой определены температура, давление и объем. В системах второго типа микроскопические изменения на низшем уровне могут возрасти до такой степени, что в результате заметно изменится макроскопический уровень. Примером такой системы является сборочный конвейер. Если один из сборщиков ошибется, с конвейера сойдет бракованная деталь.
Компьютер — это сложная комбинация систем обоих типов. Его провода представляют собой предсказуемую систему: они проводят электричество в соответствии с законом Ома. Этот весьма точный закон похож на законы, описывающие поведение газа в баллоне, поскольку он зависит от статистических эффектов: хаотическое поведение биллионов частиц дает в результате предсказуемое общее поведение системы. Компьютер также содержит макроскопические части, такие как печатающее устройство, чье поведение задается определенными электрическими импульсами. То, что печатает это устройство, ни в коей мере не является результатом мириад взаимоуничтожающих микроскопических эффектов. В большинстве компьютерных программ значение каждого бита играет важную роль в том, что напечатает компьютер. От изменения любого бита информации значительно изменяется и конечный результат.
Системы, состоящие только из «надежных» подсистем, — то есть таких подсистем, чье поведение может быть с уверенностью предсказано на основании описания их частей, — играют важнейшую роль в нашей повседневной жизни, поскольку они являются оплотом стабильности. Мы можем быть уверены, что стены не упадут нам на голову, что тротуар окажется сегодня там же, где вчера, что солнце не исчезнет с небосвода, что часы показывают правильное время и так далее. Блочные модели подобных систем практически полностью детерминисткие. Разумеется, другой тип системы, играющей важную роль в нашей жизни, это система, чье поведение варьируется в зависимости от внутренних микроскопических параметров, — зачастую огромного множества таких параметров, — которые не поддаются прямому наблюдению. Наша блочная модель подобной системы будет выражаться в терминах некоего «пространства» ее действия и будет включать вероятностные оценки того, в каком месте этого пространства «приземлится» система в данный момент.
Баллон с газом, который, как я уже сказал, является надежной системой в результате множества взаимоуничтожающих микроскопических эффектов, подчиняется точным, детерминистким законам физики. Это
Важно иметь в виду, что закон высшего уровня не может быть выражен в терминах низших уровней. «Давление» и «температура» — новые термины, которые не могут быть поняты только на основании низшего уровня. Мы, люди, прямо воспринимаем температуру и давление, поскольку мы так устроены, не удивительно, что мы открыли этот закон. Но существа, которые воспринимали бы газы как абстрактные математические конструкции, должны были бы обладать умением выводить новые понятия, чтобы открыть подобный закон.
В завершение этой главы я хотел бы рассказать забавную историю о сложных системах. Однажды я беседовал с двумя программистами, работавшими с операционной системой компьютера, который я использовал. Они сказали, что она запросто справляется со своей задачей, когда к ней подключено менее тридцати пяти человек; но когда это число достигает тридцати пяти, время ответа внезапно замедляется настолько, что с таким же успехом можно отключиться от системы, пойти домой и вернуться попозже. Шутя, я сказал: «Эту проблему решить ничего не стоит — для этого нужно только отыскать то место в операционной системе, где записано число „35“, и поменять его на „60“!» Все рассмеялись. Дело, разумеется, в том, что такого места просто не существует. Откуда же, в таком случае, появляется это критическое число — 35 пользователей?
Так же вы можете спросить о бегуне. «Где в нем содержится число „10“, позволяющее ему пробегать 100 метров за 10 секунд?» Ясно, что оно не содержится ни в каком специальном месте. Время, которое бегун показывает на стометровке, — результат его физического состоянии, быстроты его реакций, и миллиона других факторов, взаимодействующих между собой, когда он бежит. Это время вполне воспроизводимо, но оно не записано нигде в его теле. Оно распределено по всем клеткам его тела и проявляется только во время бега.
 |
| © 2024 Библиотека RealLib.org (support [a t] reallib.org) |