"C# для профессионалов. Том II" - читать интересную книгу автора (Робинсон Симон, Корнес Олли, Глинн Джей,...)
Данные ADO.NET в документе XML
Первый пример, который будет рассмотрен, использует потоки ADO.NET и XML для извлечения данных из базы данных Northwind в DataSet, загрузки объекта XmlDocument, содержащего XML, из DataSet, и загрузки XML в listbox аналогично тому, что делалось ранее. Чтобы выполнить несколько следующих примеров, необходимо добавить инструкции using:
using System.Data;
using System.Xml;
using System.Data.SqlClient;
using System.IO;
Также для примеров ADO в формы добавлены DataGrid, что позволит нам увидеть данные в DataSet из ADO.NET, так как они ограничены сеткой, а также данные из созданных документов XML, которые загружаются в listbox. Вот код первого примера, который можно найти в папке ADOSample1:
private void button1_Click(object sender, System.EventArgs e) {
// создать множество данных DataSet
DataSet ds=new DataSet("XMLProducts");
// соединиться с базой данных northwind и
//выбрать все строки из таблицы продуктов
//убедитесь, что имя пользователя соответствует версии SqlServer
SqlConnection conn=
new SqlConnection(@"server=GLYNNJ_CS\NetSDK;uid=sa;pwd=;database=northwind");
SqlDataAdapter da=new SqDataAdapter("select * from products", conn);
После создания SqlDataAdapter, da и DataSet, ds создаются экземпляры объекта MemoryStream, объекта StreamReader и объекта StreamWriter. Объекты StreamReader и StreamWriter будут применять MemoryStream для перемещения XML:
MemoryStream memStrm=new MemoryStream();
StreamReader strmRead=new StreamReader(memStrm);
StreamWriter strmWrite=new StreamWriter(memStrm);
Мы будем использовать MemoryStream, поэтому ничего на диск записываться не будет, однако мы сможем применять любые объекты на основе класса Stream, такие как FileStream. Затем мы заполним DataSet и свяжем его с DataGrid. Данные из DataSet будут выводиться теперь в DataGrid:
da.Fill(ds, "products");
// загрузка данных в DataGrid
dataGrid1.DataSource=ds;
dataGrid1.DataMember="products";
На следующем шаге генерируется XML. Вызывается метод WriteXml из класса DataSet. WriteXml генерирует документ XML. Существуют две перегружаемые версии WriteXml, одна получает строку с путем доступа и именем файла, а в другом методе добавлен параметр режима mode. Этот mode является перечислением XmlWriteMode. Возможными значениями являются DiffGram, IgnoreSchema, и WriteSchema. Обсудим DiffGram позже в этом разделе. IgnoreSchema используется, если нежелательно, чтобы WriteXml записывал подставляемую (inline) схему в файл XML; используйте параметр WriteSchema, если это желательно. Чтобы получить именно схему, вызывается WriteXmlSchema. Этот метод имеет четыре перегружаемые версии. Одна получает строку, содержащую путь доступа и имя файла, куда записывается документ XML. Вторая версия использует объект, который основывается на классе XmlWriter. Третья версия использует объект, который основывается на классе TextWriter. Четвертая версия используется в примере, параметр в этом случае является производным от класса Stream:
ds.WriteXml(strmWrite, XmlWriteMode.IgnoreSchema);
memStrm.Seek(0, SeekOrigin, Begin);
// читаем из потока в памяти в объект XmlDocument
doc.load(strmRead);
// получить все элементы продуктов
XmlNodeList nodeLst=doc.GetElementsByTagName("ProductName");
// загрузить их в окно списка
foreach(XmlNode nd in nodeLst) listBox1.Items.Add(nd.InnerText);
}
private void listBox1_SelectedIndexChanged(object sender, System.EventArgs e) {
// при щелчке в окне списка
// появляется окно сообщения с ценой изделия
string srch=
"XmlProducts/products[ProductName= " + '"' + listBox1.SelectedItem.ToString() + "]";
XmlNode foundNode=doc.SelectSingleNode(srch);
if (foundNode!=null)
MessageBox.Show(foundNode.SelectSingleNode("UnitPrice").InnerText);
else MessageBox.Show("Not found");
}
На следующем экране можно видеть данные в списке, а также в таблице данных:
 |
Если желательно сохранить документ XML на диске, то нужно сделать примерно следующее:
string file = "с:\\test\\product.xml";
ds.WriteXml(file);
Это даст нам правильно сформированный документ XML на диске, который можно прочитать посредством другого потока, с помощью DataSet, или может использоваться другим приложением или web-сайтом. Так как никакого параметра XmlMode не определено, этот документ XmlDocument будет содержать схему. В нашем примере в качестве параметра для метода XmlDocument.Load используется поток.
Когда XmlDocument подготовлен, мы загружаем listbox с помощью того же объекта XPath, который использовался раньше. Если посмотреть внимательно, то можно заметить, что слегка изменено событие listBox1_SelectedIndexChanged. Вместо вывода InnerText элемента, выполняется другой поиск XPath с помощью SelectSingleNode, чтобы получить элемент UnitPrice. Каждый раз при щелчке на продукте в listbox будет появляться MessageBox для UnitPrise. Теперь у нас есть два представления данных, но более важно то, что имеется возможность манипулировать данными с помощью двух различных моделей. Можно использовать пространство имен Data для данных или пространство имен XML через данные. Такой подход ведет к очень гибким конструкциям в приложениях, так как теперь при программировании нет жесткой связи только с одной объектной моделью. Таким образом, мы имеем несколько представлений одних и тех же данных и несколько способов доступа к данным.
Следующий пример будет упрощать процесс, удаляя три потока и используя некоторые возможности ADO, встроенные в пространство имен XML. Нам понадобится изменить строку кода на уровне модуля:
private XmlDocument doc=new XmlDocument();
на:
private XmlDataDocument doc;
Это нужно сделать, так как мы не собираемся использовать XmlDataDocument. Вот код, который можно найти в папке ADOSample2:
private void button1_Click(object sender, System.EventArgs e) {
// создать множество данных (DataSet)
DataSet ds=new DataSet("XMLProducts");
// соединиться с базой данных northwind и
//выбрать все строки из таблицы products
//выполнить изменения в строке подключения с учетом имени пользователя и имени сервера
SqlConnection conn=
new SqlConnection(@"server=GLYNNJ_CS\NetSDK;uid=sa;pwd=;database=northwind");
SqlDataAdapter da=new SqlDataAdapter("select * from products", conn);
// заполнить множество данных
da.Fill(ds, "products");
// загрузить данные в сетку
dataGrid1.DataSource=ds;
dataGrid1.DataMember="products";
doc=new XmlDataDocument(ds);
// извлечь все элементы продуктов
XmlNodeList nodeLst=doc.GetElementsByTagName("ProductName");
// загрузить их в окно списка
// здесь используется цикл for
for(int ctr=0; ctrlt;nodeLst.Count; ctr++) listBox1.Items.Add(nodeLst[ctr].InnerText);
}
Как можно видеть, код для загрузки DataSet в документ XML был упрощен. Вместо использования класса XmlDocument, используется класс XmlDataDocument. Этот класс был создан специально для использования данных с объектом DataSet.
XmlDataDocument базируется на классе XmlDocument, поэтому он имеет всю функциональность класса XmlDocument. Одним из основных отличий является перегруженный конструктор для XmlDataDocument. Отметим строку кода, где создается экземпляр XmlDataDocument:
XmlDataDocument doc=new XmlDataDocument(ds);
Он передает в качестве параметра созданный объект DataSet, ds. Документ XML создается из множества данных, поэтому не требуется использование метода Load. Существует также свойство DataSet, которое может задаваться с помощью текущего свойства DataSet. Фактически, если создается новый объект XmlDataDocument без передачи DataSet в качестве параметра, то он содержит объект DataSet с именем NewDataSet, который не имеет DataTables в коллекции таблиц. Существует также свойство DataSet, которое можно установить после создания объекта на основе XmlDataDocument. Если после вызова DataSet.Fill добавляется следующая строка кода:
ds.WriteXml("с:\\test\\sample.xml" , XmlWriteMode, WriteSchema);
…создается следующий XML. Отметим, что мы включили в документ схему XSD. Если нежелательно, чтобы схема включалась в файл, то можно передать член перечисления XmlWriteMode.IgnoreSchema:
lt;?xml version="1.0" standalone="yes"?gt;
lt;XMLProductsgt;
lt;xsd:schema id="XMLProducts" targetNamespace="" xmlns="" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:msdata="urn:schemas-microsoft-com:xml-msdata"gt;
lt;xsd:element name="XMLProducts" msdata:IsDataSet="true"gt;
lt;xsd:complexTypegt;
lt;xsd:choice maxOccurs="unbounded"gt;
lt;xsd:element name="products"gt;
lt;xsd:complexTypegt;
lt;xsd:sequencegt;
lt;xsd:element name="ProductID" type="xsd:int" minOccurs="0" /gt;
lt;xsd:element name="ProductName" type="xsd:string" minOccurs="0" /gt;
lt;xsd:element name="SupplierID" type="xsd:int" minOccurs ="0" /gt;
lt;xsd:element name="CategoryID" type="xsd:int" minOccurs="0" /gt;
lt;xsd:element name="QuantityPerUnit" type="xsd:string" minOccurs="0" /gt;
lt;xsd:element name="UnitPrice" type="xsd:decimal" minOccurs="0" /gt;
lt;xsd:element name="UnitsInStock" type="xsd:short" minOccurs="0" /gt;
lt;xsd:element name="UnitsOnOrder" type="xsd:short" minOccurs="0" /gt;
lt;xsd:element name="ReorderLevel" type="xsd:short" minOccurs="0" /gt;
lt;xsd:element name="Discontinued" type="xsd:boolean" minOccurs="0" /gt;
lt;/xsd:sequencegt;
lt;/xsd:сomplexTypegt;
lt;/xsd:elementgt;
lt;/xsd:choicegt;
lt;/xsd:complexTypegt;
lt;/xsd:elementgt;
lt;/xsd:schemagt;
lt;productsgt;
lt;ProductIDgt;1lt;/ProductIDgt;
lt;ProductNamegt;Chailt;/ProductNamegt;
lt;SupplierIDgt;1lt;/SupplierIDgt;
lt;CategoryIDgt;1lt;/CategoryIDgt;
lt;QuantityPerUnitgt;10 boxes x 20 bagslt;/QuantityPerUnitgt;
lt;UnitPricegt;18lt;/UnitPricegt;
lt;UnitsInStockgt;39lt;/UnitsInStockgt;
lt;UnitsOnOrdergt;0lt;/UnitsOnOrdergt;
lt;ReorderLevelgt;10lt;/ReorderLevelgt;
lt;Discontinuedgt;falselt;/Discontinuedgt;
lt;/productsgt;
lt;productsgt;
lt;ProductIDgt;2lt;/ProductIDgt;
lt;ProductNamegt;Changlt;/ProductNamegt;
lt;SupplierIDgt;1lt;/SupplierIDgt;
lt;CategoryIDgt;1lt;/CategoryIDgt;
lt;QuantityPerUnitgt;24 - 12 oz bottleslt;/QuantityPerUnitgt;
lt;Unitpricegt;19lt;/UnitPricegt;
lt;UnitsInStockgt;17lt;/UnitsInStockgt;
lt;UnitsOnOrdergt;40lt;/UnitsOnOrdergt;
lt;ReorderLevelgt;25lt;/ReorderLevelgt;
lt;Discontinuedgt;falselt;/Discontinuedgt;
lt;/productsgt;
lt;/XMLProductsgt;
Показаны только два первых продукта. Реальный файл XML будет содержать все продукты из таблицы Products базы данных Northwind.
Это выглядит достаточно просто для одной таблицы, но что будет для реляционных данных, таких как несколько DataTables и Relations в DataSet? Все по-прежнему работает таким же образом. Внесем следующие изменения в коде (эту версию можно найти в ADOSample3):
private void button1_Click(object sender, System.EventArgs e) {
//создать множество данных (DataSet)
DataSet ds=new DataSet("XMLProducts");
// соединиться с базой данных northwind и
//выбрать все строки из таблицы products и таблицы suppliers
//проверьте, что строка соединения соответствует конфигурации сервера
SqlConnection conn=
new SqlConnection(@"server=GLYNNJ_CS\NetSDK;uid=sa;pwd=;database=northwind");
SqlDataAdapter daProd=new SqlDataAdapter("select * from products", conn);
SqlDataAdapter daSup=new SqlDataAdapter("select * from suppliers", conn);
//Заполнить DataSet из обоих SqlAdapters
daProd.Fill(ds, "products");
daSup.Fill(ds, "suppliers");
//Добавить отношение
ds.Relations.Add(ds.Tables["suppliers"].Columns["SupplierId"],
ds.Tables["products"].Columns["SupplierId"]);
//Записать Xml в файл, чтобы можно было просмотреть его позже
ds.WriteXml("..\\..\\..\\SuppProd.xml", XmlWriteMode.WriteSchema);
//загрузить данные в таблицу
dataGrid1.DataSource=ds;
dataGrid1.DataMember="suppliers";
//создать XmlDataDocument
doc=new XmlDataDocument(ds);
//Выбрать элементы productname и загрузить их в таблицу
XmlNodeList nodeLst=doc.SelectNodes("//ProductName");
foreach(XmlNode nd in nodeLst) listBox1.Items.Add(nd.InnerXml);
}
В этом примере создаются два объекта DataTables в DataSet из XMLProducts: Products и Suppliers. Отношение состоит в том, что Suppliers (Поставщики) поставляют Products (Продукты). Мы создаем новое отношение на столбце SupplierId в обоих таблицах. Вот как выглядит DataSet:
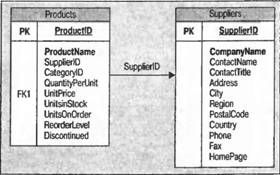 |
Делая такой же вызов метода WriteXml, как в предыдущем примере, мы получим следующий файл XML (SuppProd.xml):
lt;?xml version="1.0" standalone="yes"?gt;
lt;XMLProductsgt;
lt;xsd:schema id="XMLProducts" targetNamespace="" xmlns="" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:msdata="urn:schemas-microsoft-com:xml-msdata"gt;
lt;xsd:element name="XMLProducts" msdata:IsDataSet="true"gt;
lt;xsd:complexTypegt;
lt;xsd:choice maxOccurs="unbounded"gt;
lt;xsd:element name="products"gt;
lt;xsd:complexTypegt;
lt;xsd:sequencegt;
lt;xsd:element name="Product ID" type="xsd:int" minOccurs="0" /gt;
lt;xsd:element name="ProductName" type="xsd:string" minOccurs="0" /gt;
lt;xsd:element name="SupplierID" type="xsd:int" minOccurs="0" /gt;
lt;xsd:element name="CategoryID" type="xsd:int" minOccurs="0" /gt;
lt;xsd:element name="QuantityPerUnit" type="xsd:string" minOccurs="0" /gt;
lt;xsd:element name="UnitPrice" type="xsd:decimal" minOccurs="0" /gt;
lt;xsd:element name="UnitsInStock" type="xsd:short" minOccurs="0" /gt;
lt;xsd:element name="UnitsOnOrder" type="xsd:short" minOccurs="0" /gt;
lt;xsd:element name="ReorderLevel" type="xsd:short" minOccurs="0" /gt;
lt;xsd:element name="Discontinued" type="xsd:boolean" minOccurs="0" /gt;
lt;/xsd:sequencegt;
lt;/xsd:complexTypegt;
lt;/xsd:elementgt;
lt;xsd:element name="suppliers"gt;
lt;xsd:complexTypegt;
lt;xsd:sequencegt;
lt;xsd:element name="SupplierID" type="xsd:int" minOccurs="0" /gt;
lt;xsd:element name="CompanyName" type="xsd:string" minOccurs="0" /gt;
lt;xsd:element name="ContactName" type="xsd:string" minOccurs="0" /gt;
lt;xsd:element name="ContactTitle" type="xsd:string" minOccurs="0" /gt;
lt;xsd:element name="Address" type="xsd:string" minOccurs="0" /gt;
lt;xsd:element name="City" type="xsd:string" minOccurs="0" /gt;
lt;xsd:element name="Region" type="xsd:string" minOccurs="0" /gt;
lt;xsd:element name="PostalCode" type="xsd:string" minOccurs="0" /gt;
lt;xsd:element name="Country" type="xsd:string" minOccurs="0" /gt;
lt;xsd:element name="Phone" type="xsd:string" minOccurs="0" /gt;
lt;xsd:element name="Fax" type="xsd:string" minOccurs="0" /gt;
lt;xsd:element name="HomePage" type="xsd:string" minOccurs="0" /gt;
lt;/xsd:sequencegt;
lt;/xsd:complexTypegt;
lt;/xsd:elementgt;
lt;/xsd:choicegt;
lt;/xsd:complexTypegt;
lt;xsd:unique name="Constraint1"gt;
lt;xsd:selector xpath=".//suppliers" /gt;
lt;xsd:field xpath="SupplierID" /gt;
lt;/xsd:uniquegt;
lt;xsd:keyref name="Relation1" refer="Constraint1"gt;
lt;xsd:selector xpath=".//products" /gt;
lt;xsd:field xpath="SupplierID" /gt;
lt;/xsd:keyrefgt;
lt;/xsd:elementsgt;
lt;/xsd:schemagt;
lt;productsgt;
lt;ProductIDgt;1lt;/ProductIDgt;
lt;ProductNamegt;Chailt;/ProductNamegt;
lt;SupplierIDgt;1lt;/SupplierIDgt;
lt;CategoryIDgt;1lt;/CategoryIDgt;
lt;QuantityPerUnitgt;10 boxes x 20 bagslt;/QuantityPerUnitgt;
lt;UnitPricegt;18lt;/UnitPricegt;
lt;UnitsInStockgt;39lt;/UnitsInStockgt;
lt;UnitsOnOrdergt;0lt;/UnitsOnOrdergt;
lt;ReorderLevelgt;10lt;/ReorderLevelgt;
lt;Discontinuedgt;falselt;/Discontinuedgt;
lt;/productsgt;
lt;productsgt;
lt;ProductIDgt;2lt;/ProductIDgt;
lt;ProductNamegt;Changlt;/ProductNamegt;
lt;SupplierIDgt;1lt;/SupplierIDgt;
lt;CategoryIDgt;1lt;/CategoryIDgt;
lt;QuantityPerUnitgt;24 - 12 oz bottleslt;/QuantityPerUnitgt;
lt;UnitPricegt;19lt;/UnitPricegt;
lt;UnitsInStockgt;17lt;/UnitsInStockgt;
lt;UnitsOnOrdergt;40lt;UnitsOnOrdergt;
lt;ReorderLevelgt;25lt;/ReorderLevelgt;
lt;Discontinuedgt;falselt;/Discontinuedgt;
lt;/productsgt;
lt;suppliersgt;
lt;SupplierIDgt;1lt;/SupplierIDgt;
lt;CompanyNamegt;Exotiс Liquidslt;/CompanyNamegt;
lt;ContactNamegt;Charlotte Cooperlt;/ContactNamegt;
lt;ContactTitlegt;Purchasing Managerlt;/ContactTitlegt;
lt;Addressgt;49 Gilbert St.lt;/Addressgt;
lt;Citygt;Londonlt;/Citygt;
lt;PostalCodegt;EC1 4SDlt;/PostalCodegt;
lt;Countrygt;UKlt;/Countrygt;
lt;Phonegt;(171) 555-2222lt;/Phonegt;
lt;/suppliersgt;
lt;suppliersgt;
lt;Supplier IDgt;2lt;/SupplierIDgt;
lt;CompanyNamegt;New Orleans Cajun Delightslt;/CompanyNamegt;
lt;ContactNamegt;Shelley Burkelt;/ContactNamegt;
lt;ContactTitlegt;Order Adminisiratorlt;/ContactTitlegt;
lt;Addressgt;P.O. Box 78934lt;/Addressgt;
lt;Citygt;New Orleanslt;/Citygt;
lt;Regiongt;LAlt;/Regiongt;
lt;PostalCodegt;70117lt;/PostalCodegt;
lt;Countrygt;USAlt;/Countrygt;
lt;Phonegt;(100) 555-4822lt;/Phonegt;
lt;HomePagegt;#CAJUN.HTM#lt;/HomePagegt;
lt;/suppliersgt;
lt;/XMLProductsgt;
Эта схема включает в себя обе таблицы данных DataTables, которые находились в DataSet. Данные также содержат все данные из обеих таблиц. Несколько продуктов и поставщиков были удалены из окончательного файла, чтобы сэкономить пространство. Как и раньше, можно сохранить только схему или только данные, передавая соответствующий параметр XmlWriteMode.
| © 2025 Библиотека RealLib.org (support [a t] reallib.org) |