"Создание электронных книг из сканов. DjVu или Pdf из бумажной книги легко и быстро" - читать интересную книгу автора (TWDragon)
4.4 Финальная вычитка и подготовка версии для PDA
Итак, книга для просмотра на мониторе или еВоок подготовлена. Но, если только это не технический справочник, вам наверняка охота получить еще и маленький файл для загрузки на PDA или любимый сотовый телефончик. Получить его будет опять-таки довольно утомительно, но фактически совсем не сложно. Берем пакет с распознанной книгой, открываем его в FineReader и сохраняем в формате ТХТ. Потом — открываем полученный файл в MS Word и приступаем к финальной вычитке. Тут самой главной проблемой будут оставленнные программами дефисы на месте переносов. Их удаление будет весьма монотонной, но достаточно быстрой работой. Лучше всего открытый в Word файл перевести в режим отображения «Веб-документ». Теперь остается только, прокручивая текст, искать неверные переносы на правой стороне экрана, и исправлять их. Переносы в FineReader не изменяются в таких случаях:
• Если слово с переносом расположено в конце страницы (перенос идет на следующую страницу);
• Если слова с переносом нет в словаре FineReader (словарь длиной не отличается, так что подавляющее большинство имен и фамилий, вся историческая и научная терминология — в группе риска).
Когда текст вычитан, наступает время заголовков и рисунков. Каких-либо рекомендаций по выделению заголовков — давать нет смысла, ибо кому что нравится. С рисунками придется повозиться чуть дольше. Во-первых, те из рисунков, которые были обозначены как диффузные (
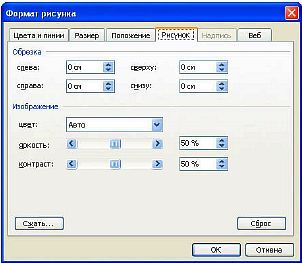 |
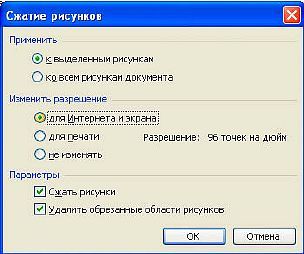 |
Сохранять полученный файл лучше всего в формат HTML. Как показала практика, с ним не возникает проблем у большинства «читательных» программ на мобильных телефонах и PDA. Отдельные энтузиасты могут попробовать преобразовать полученный текст в набирающий популярность XML-совместимый формат FB2, но описание этого процесса требует отдельного руководства, так как для редактирования FB2 еще не создано устоявшегося набора удобных в использовании визуальных программ-редакторов. Можно попробовать преобразовать файл HTML в формат FB2 с помощью консольной утилиты AnyToFB2.ехе, но работа с ней выходит за рамки данного руководства. Для того чтобы выходной HTML-файл был совместим с основным WEB-стандартом HTML (не содержал служебной информации Word, отформатированной по спецификации Microsoft, не совместимой со стандартным HTML), сохранять нужно, задав в списке «Тип файла» пункт «Веб-страница с фильтром». При выборе этого пункта Word сперва спросит, в своем ли мы уме, что не сохраняем его служебные данные, но потом выведет в указанную папку две вещи: собственно HTML-файл lt;имя книгиgt;.html с текстом книги, и подпапку с именем \lt;имя книгиgt;.files\ которая будет содержать сжатые рисунки и XML-таблицу совместимости Word.
Эти две вещи лучше всего сразу запаковать в ZIP-архив (большинство программ-читателей, вроде AlReader — сможет распаковать такие книги), чтобы ничего не потерять при переносе на мобильное устройство и не плодить в памяти отдельные папки под каждую книгу.
По завершении всех операций — вы получаете электронную книгу, практически неотличимую на вид (правда, на экране) от бумажной! Плюс версия для чтения на мобильнике.
Еще раз повторю: описать все эти операции гораздо труднее, чем выполнить их одну за другой.
Удачи в книгосканировании!
P.S. Примеры к этому руководству я получил, отсканировав и обработав книгу Лины Хааг «Горсть пыли». Если Вы хотите посмотреть, к чему приводит точное и неукоснительное исполнение правил, изложенных в руководстве — скачайте книгу по адресу http://torrents.ru/forum/viewtopic.php?t=2170096. Кроме того, эта книга сама по себе может быть весьма полезной, особенно любителям истории Второй мировой войны.
| © 2024 Библиотека RealLib.org (support [a t] reallib.org) |