"Создание электронных книг из сканов. DjVu или Pdf из бумажной книги легко и быстро" - читать интересную книгу автора (TWDragon)
1.2 Сканирование
Заранее хочу предостеречь от использования в качестве основного инструмента сканирования программы FineReader. Оставим эту программу до стадии OCR. Пока она может лишь максимально усложнить нам задачу пакетной обработки, применив (причем, без нашего ведома) — свои не слишком хорошие алгоритмы чистки и сжатия сканов. А главное — она практически лишит нас шансов применить важнейший прием — оверсемплинг до разрешения 600 dpi.
Собственно сканирование состоит из трех этапов:
Здесь приведу еще одно важнейшее предупреждение(!):
На некоторых очень старых моделях сканеров есть возможность вручную включать внутренний оверсемплинг, тo есть фактически сканировать с меньшим разрешением, чем имеет выходной файл. Обозначается такая установка разрешения обычно словом
Общие рекомендации такие: для текстовых страниц используйте:
• Режим
• Разрешение сканирования — 300 dpi (только оптическое, повторимся еще раз!).
• Остальные установки можно оставить по умолчанию.
Таблица 1. Оптимальные параметры сканирования
Эти параметры не являются догмой. Они определены опытным путем на нескольких моделях неспециализированных сканеров, и служат ориентировочным целям. Собственный набор оптимальных параметров книгосканирования всегда стоит определить экспериментально, отсканировав любимую книгу со всеми иллюстрациями и обложкой. Приводя эти параметры, я стремился обобщить их для применения на максимальном количестве моделей сканеров.
Тип страницы: Страница с черно-белым текстом без иллюстраций
Режим: Grayscale
Разрешение: 300 dpi
Резкость: Low или Medium
Яркость и контраст: Любые, специальные параметры не использовать
Тип страницы: Страница с черно-белым текстом и черно-белыми штриховыми (одноцветными) иллюстрациями
Режим: Grayscale
Разрешение: 300 dpi
Резкость: Medium. High
Яркость и контраст: Любые, можно применить пресет Bamp;W Photo
Тип страницы: Страница с черно-белым текстом и черно-белыми фотографическими иллюстрациями
Режим: Grayscale
Разрешение: 300 dpi
Резкость: High можно применить пресет Bamp;W Photo
Яркость и контраст: Определяются по предварительному сканированию
Тип страницы: Страница с черно-белым текстом и цветными иллюстрациями
Режим: True Color
Разрешение: 300 dpi
Резкость: Low, можно применить пресет Photo
Яркость и контраст: Определяются по предварительному сканированию
Тип страницы: Цветная обложка или иллюстрация страничного формата
Режим: True Color
Разрешение: 300 dpi
Резкость: Low, можно применить пресет Photo
Яркость и контраст: Определяются по предварительному сканированию
Формат выходного файла:
Почему не JPEG?
Формат JPEG для сохранения сканов книжных страниц использовать можно, но не нужно.
Во-первых: потому, что этот формат даже при включенном сжатии без потерь (Quality = 100) оставляет артефакты в виде «квадратиков».
Во-вторых и самых главных: многократное пережатие при сохранении обработанного файла JPEG вновь в «свой» формат за 2–3 цикла обработки приводит изображение в негодность.
Отдельно коснемся использования сжатого (Compressed) TIFF: при сохранении сжатого изображения в TIFF можно использовать алгоритмы сжатия: ZIP. LZW (без потерь). JPEG (с потерями). Без хлопот программы распознавания вроде FineReader понимают только JPEG.
Со всеми остальными форматами проблемы могут возникать непредсказуемо (например, у меня FineReader 7.0 испытывает устойчивую «идиосинкразию» конкретно к формату сжатия LZW). Поэтому если нет особых проблем с наличием места на диске, лучше всегда использовать несжатый файл.
Итак, сканер включен, программа управления запущена.
Кладем книгу на предметное стекло сканера таким образом, чтобы охватить обложку (с нее лучше всего начинать сканирование). Включаем предварительное сканирование и настраиваем изображение инструментами программы управления сканером, добиваясь максимального соответствия оригиналу. Когда параметры выставлены, сохраняем переднюю и заднюю страницы обложки в файлы с информативными именами (типа
Отсканировав обложку, вновь кладем книгу на стекло, но уже с открытой первой страницей и форзацем (если сканер имеет форматный фактор на стекле А4 или А4+? книгу с форматом страницы более А5 придется сканировать по одной странице, при этом придется отдельно сохранить форзацы). Предварительное сканирование запускаем еще раз. Параметры теперь нужно выставить таким образом, чтобы добиться хорошей контрастности текста и черно-белых иллюстраций.
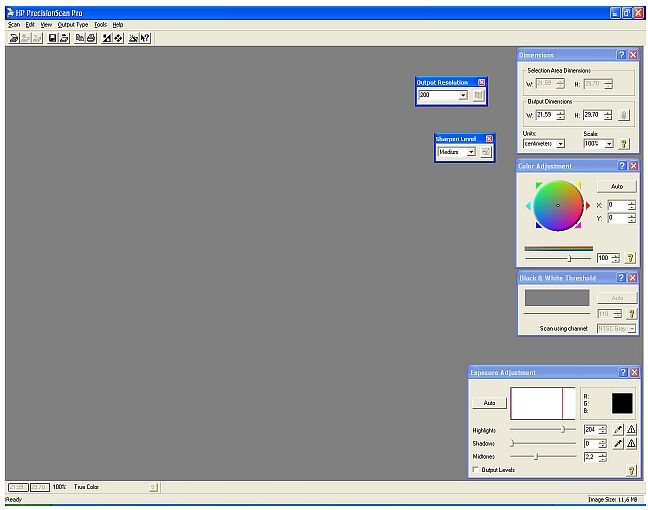 |
Установка_области сканирования: область сканирования для книг (особенно при сканировании разворотами) — выставляется с запасом относительно формата книги, чтобы не особенно заботиться в дальнейшем о выравнивании книги на стекле. Это очень ускоряет работу: если не «швырять» книгу на сканер как попало — текст и хотя бы часть полей обязательно попадут в установленную область, а выравнивание изображения можно будет сделать при обработке. Задаем папку для сохранения выходных данных сканера. В зависимости от того, сканируется разворот книги, или одна страница, выбираем имя для первого файла.
 |
Из личного опыта:
Поработав с несколькими десятками книг, я пришел к выводу, что нумерацию файлов со сканами лучше всего начинать с нуля (например, Scan_000.TIF). Дело в том. что нумерация страниц в книгах обычно идет по схеме: Форзац =gt; Страница 1 (как правило, без номера) =gt; Страница 2 (данные типографии) =gt; Прочие страницы. Если сканировать книгу разворотами, то при нумерации с нуля номер каждого файла будет в точности равен номеру четной страницы, разделенному на 2, то есть:
1. Разворот 1 (Форзац и страница номер 1) — файл с именем Scan_000. TIF;
2. Разворот 2 (страницы 2 и 3) — файл с именем Scan_001. TIF;
3. Разворот 3 (страницы 4 и 5) — файл с именем Scan 002. TIF;
4. Итак далее…
Как правило, сканы именует сама программа сканирования, когда включен ее пакетный режим. Тогда заботиться об именах вообще не нужно. Однако у меня автоматическое именование работает (причем плохо) — только когда включен модуль автоматического листового сканирования ScanJet ADF. Поэтому я стараюсь давать своим файлам вручную простейшие цифровые имена, набивая их на нумпаде (заодно руки отдыхают от постоянного нажатия Ctrl+S).
Облегчить себе работу при сканировании — максимально насущная задача.
Если сканирование каждого отдельного разворота/листа включается клавишами (например теми же Ctrl+S) — нет проблем. Просто не меняя параметров области сканирования — жмете клавиши еще раз, набираете (или не набираете, если повезло с программой) имя очередного файла — и ждете окончания процесса. Если же без нажатия кнопки мыши не обойтись — ставите курсор на кнопку включения сканирования, и по окончании прохода очередной страницы — щелкаете пальцем по мышке, не сдвигая ее. При этом дожидаться, пока головка сканера вернется в исходное положение — никак не обязательно! Это только замедлит работу.
Описанным способом, в зависимости от быстродействия сканера, на один разворот уходит в среднем 18–25 секунд. То есть, при небольшом навыке можно выйти на «производительность ударного труда» порядка 160–200 разворотов (360–400 страниц) в час. Это значит, что в среднем за пару часов вы способны управиться даже с самыми толстыми томами! Немного усидчивости — и вуаля.
Маленькие хитрости
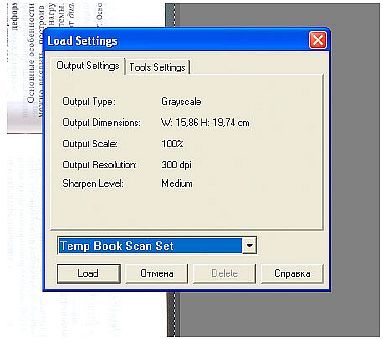 |
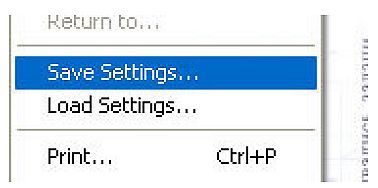
Крайне желательно, чтобы программа сканирования имела обновляемые преcеты установок области и параметров сканирования. Тогда, не закончив вечером работу над очередным томом, можно сохранить установки сканера, а потом — просто загрузить их.
 |
В целом, чем проще будет для вас процесс сканирования — тем лучше. Главное для получения хорошего результата — следовать самым простым описанным правилам — получать выходной файл в формате несжатого TIFF, с разрешением 300dpi. Ну, и, само собой разумеется, в готовых файлах вы сами должны быть способны, не напрягаясь, прочитать текст.
| © 2024 Библиотека RealLib.org (support [a t] reallib.org) |